
本博客日IP超过2000,PV 3000 左右,急需赞助商。
极客时间所有课程通过我的二维码购买后返现24元微信红包,请加博主新的微信号:xttblog2,之前的微信号好友位已满,备注:返现
受密码保护的文章请关注“业余草”公众号,回复关键字“0”获得密码
所有面试题(java、前端、数据库、springboot等)一网打尽,请关注文末小程序

腾讯云】1核2G5M轻量应用服务器50元首年,高性价比,助您轻松上云
对文档建立好索引后,就可以在这些索引上面进行搜索了。搜索引擎首先会对搜索的关键词进行解析,然后再在建立好的索引上面进行查找,最终返回和用户输入的关键词相关联的文档。

到这里似乎我们可以宣布“我们找到想要的文档了”。
然而事情并没有结束,找到了仅仅是全文检索的一个方面。不是吗?如果仅仅只有一个或十个文档包含我们查询的字符串,我们的确找到了。然而如果结果有一千个,甚至成千上万个呢?那个又是您最想要的文件呢?
打开Google吧,比如说您想在微软找份工作,于是您输入“Microsoft job”,您却发现总共有22600000个结果返回。好大的数字呀,突然发现找不到是一个问题,找到的太多也是一个问题。在如此多的结果中,如何将最相关的放在最前面呢?

当然Google做的很不错,您一下就找到了jobs at Microsoft。想象一下,如果前几个全部是“Microsoft does a good job at software industry…”将是多么可怕的事情呀。
如何像Google一样,在成千上万的搜索结果中,找到和查询语句最相关的呢?
如何判断搜索出的文档和查询语句的相关性呢?
这要回到我们第三个问题:如何对索引进行搜索?
搜索主要分为以下几步:
第一步:用户输入查询语句。
查询语句同我们普通的语言一样,也是有一定语法的。
不同的查询语句有不同的语法,如SQL语句就有一定的语法。
查询语句的语法根据全文检索系统的实现而不同。最基本的有比如:AND, OR, NOT等。
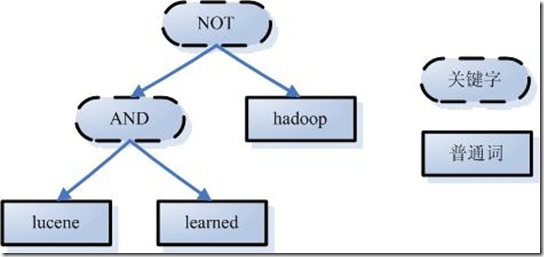
举个例子,用户输入语句:lucene AND learned NOT Hadoop。
说明用户想找一个包含lucene和learned然而不包括hadoop的文档。
第二步:对查询语句进行词法分析,语法分析,及语言处理。
由于查询语句有语法,因而也要进行语法分析,语法分析及语言处理。
1. 词法分析主要用来识别单词和关键字。
如上述例子中,经过词法分析,得到单词有lucene,learned,hadoop, 关键字有AND, NOT。
如果在词法分析中发现不合法的关键字,则会出现错误。如lucene AMD learned,其中由于AND拼错,导致AMD作为一个普通的单词参与查询。
2. 语法分析主要是根据查询语句的语法规则来形成一棵语法树。
如果发现查询语句不满足语法规则,则会报错。如lucene NOT AND learned,则会出错。
如上述例子,lucene AND learned NOT hadoop形成的语法树如下:
3. 语言处理同索引过程中的语言处理几乎相同。
如learned变成learn等。
经过第二步,我们得到一棵经过语言处理的语法树。
第三步:搜索索引,得到符合语法树的文档。
此步骤有分几小步:
- 首先,在反向索引表中,分别找出包含lucene,learn,hadoop的文档链表。
- 其次,对包含lucene,learn的链表进行合并操作,得到既包含lucene又包含learn的文档链表。
- 然后,将此链表与hadoop的文档链表进行差操作,去除包含hadoop的文档,从而得到既包含lucene又包含learn而且不包含hadoop的文档链表。
- 此文档链表就是我们要找的文档。
第四步:根据得到的文档和查询语句的相关性,对结果进行排序。
虽然在上一步,我们得到了想要的文档,然而对于查询结果应该按照与查询语句的相关性进行排序,越相关者越靠前。
如何计算文档和查询语句的相关性呢?
不如我们把查询语句看作一片短小的文档,对文档与文档之间的相关性(relevance)进行打分(scoring),分数高的相关性好,就应该排在前面。
那么又怎么对文档之间的关系进行打分呢?
这可不是一件容易的事情,首先我们看一看判断人之间的关系吧。
首先 看一个人,往往有很多要素 ,如性格,信仰,爱好,衣着,高矮,胖瘦等等。
其次 对于人与人之间的关系,不同的要素重要性不同 ,性格,信仰,爱好可能重要些,衣着,高矮,胖瘦可能就不那么重要了,所以具有相同或相似性格,信仰,爱好的人比较容易成为好的朋友,然而衣着,高矮,胖瘦不同的人,也可以成为好的朋友。
因而判断人与人之间的关系,首先要找出哪些要素对人与人之间的关系最重要 ,比如性格,信仰,爱好。其次要判断两个人的这些要素之间的关系 ,比如一个人性格开朗,另一个人性格外向,一个人信仰佛教,另一个信仰上帝,一个人爱好打篮球,另一个爱好踢足球。我们发现,两个人在性格方面都很积极,信仰方面都很善良,爱好方面都爱运动,因而两个人关系应该会很好。
我们再来看看公司之间的关系吧。
首先 看一个公司,有很多人组成,如总经理,经理,首席技术官,普通员工,保安,门卫等。
其次对于公司与公司之间的关系,不同的人重要性不同 ,总经理,经理,首席技术官可能更重要一些,普通员工,保安,门卫可能较不重要一点。所以如果两个公司总经理,经理,首席技术官之间关系比较好,两个公司容易有比较好的关系。然而一位普通员工就算与另一家公司的一位普通员工有血海深仇,怕也难影响两个公司之间的关系。
因而判断公司与公司之间的关系,首先要找出哪些人对公司与公司之间的关系最重要 ,比如总经理,经理,首席技术官。其次要判断这些人之间的关系 ,不如两家公司的总经理曾经是同学,经理是老乡,首席技术官曾是创业伙伴。我们发现,两家公司无论总经理,经理,首席技术官,关系都很好,因而两家公司关系应该会很好。
分析了两种关系,下面看一下如何判断文档之间的关系 了。
首先,一个文档有很多词(Term)组成 ,如search, lucene, full-text, this, a, what等。
其次对于文档之间的关系,不同的Term重要性不同 ,比如对于本篇文档,search, Lucene, full-text就相对重要一些,this, a , what可能相对不重要一些。所以如果两篇文档都包含search, Lucene,fulltext,这两篇文档的相关性好一些,然而就算一篇文档包含this, a, what,另一篇文档不包含this, a, what,也不能影响两篇文档的相关性。
因而判断文档之间的关系,首先找出哪些词(Term)对文档之间的关系最重要,如search, Lucene, fulltext。然后判断这些词(Term)之间的关系。

最后,欢迎关注我的个人微信公众号:业余草(yyucao)!可加作者微信号:xttblog2。备注:“1”,添加博主微信拉你进微信群。备注错误不会同意好友申请。再次感谢您的关注!后续有精彩内容会第一时间发给您!原创文章投稿请发送至532009913@qq.com邮箱。商务合作也可添加作者微信进行联系!
本文原文出处:业余草: » Lucene 如何对索引进行搜索?