
本博客日IP超过2000,PV 3000 左右,急需赞助商。
极客时间所有课程通过我的二维码购买后返现24元微信红包,请加博主新的微信号:xttblog2,之前的微信号好友位已满,备注:返现
受密码保护的文章请关注“业余草”公众号,回复关键字“0”获得密码
所有面试题(java、前端、数据库、springboot等)一网打尽,请关注文末小程序

腾讯云】1核2G5M轻量应用服务器50元首年,高性价比,助您轻松上云
在分布式环境当中,总是会遇到诸如 主机宕机 或 网络故障 等各种影响系统可用性的情况发生。轻则会导致投诉,重则导致企业核心数据的丢失,影响企业业绩和商誉。而如何确保分布式系统运行正常,应对各种故障场景,保证系统始终处于高可用状态是每个企业研究的方向之一。
腾讯云数据库技术专家,赵海明在PostgreSQL 2017中国技术大会上,以 腾讯分布式数据库 Tbase 的可靠性系统为例,为大家分享了保障分布式系统可靠性的一些基本思路。
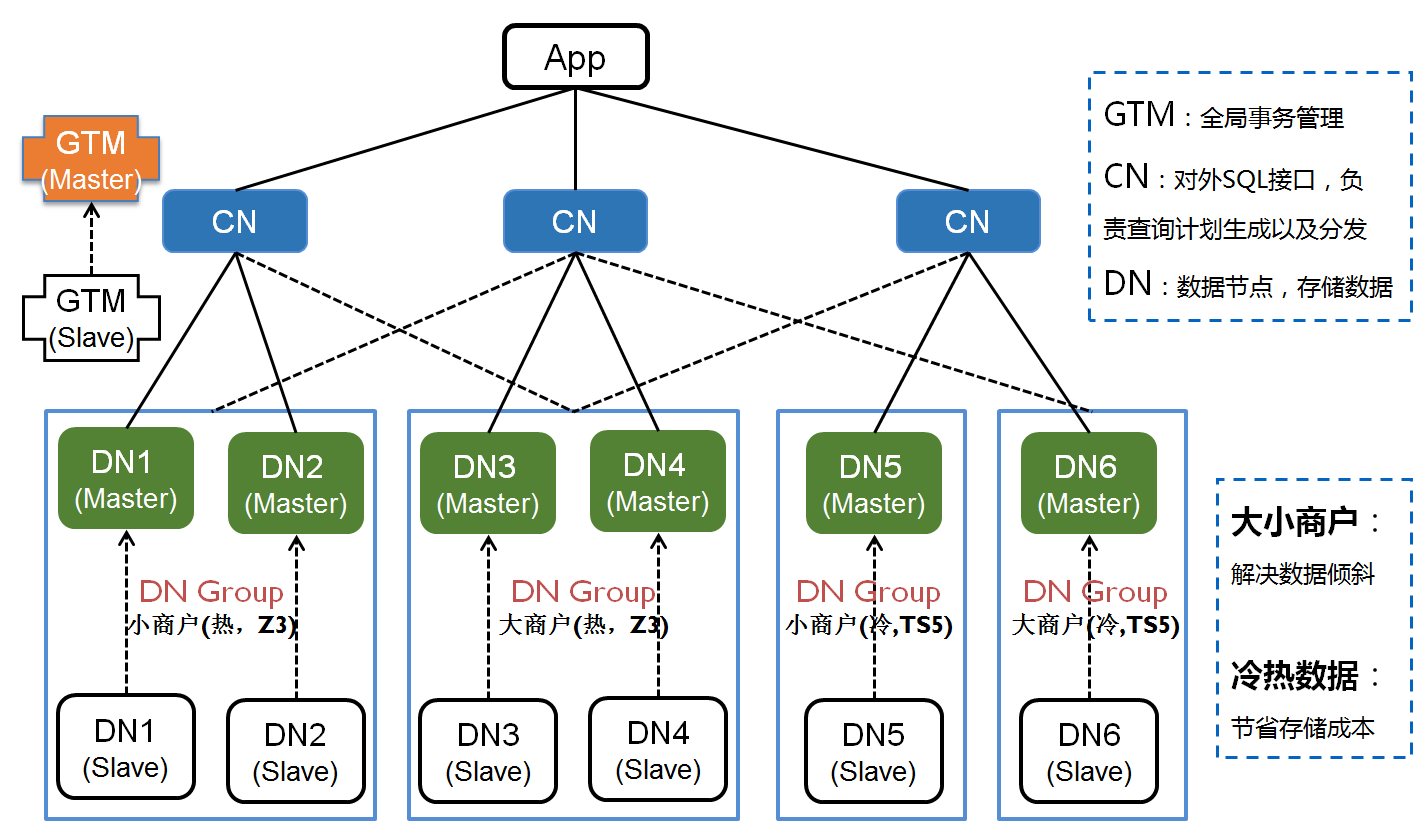
Tbase,腾讯自研全功能分布式关系数据库
Tbase 是腾讯在开源的分布式数据库PosgreSQL-XC(简称PGXC)基础上,研发的一款全功能分布式关系数据库系统,相较于PGXC,Tbase 通过在内核中创造性的引入 GROUP 的概念,提出双 KEY 分布策略,有效的解决了数据倾斜的问题;同时,根据数据的时间戳,将数据分为冷数据和热数据,分别存储与不同的存储设备中,有效的解决了存储成本的问题。本文主要以Tbase举例,自上而下向读者深度剖析保障Tbase 可靠性的两大系统:灾备系统 和 冷备系统 。
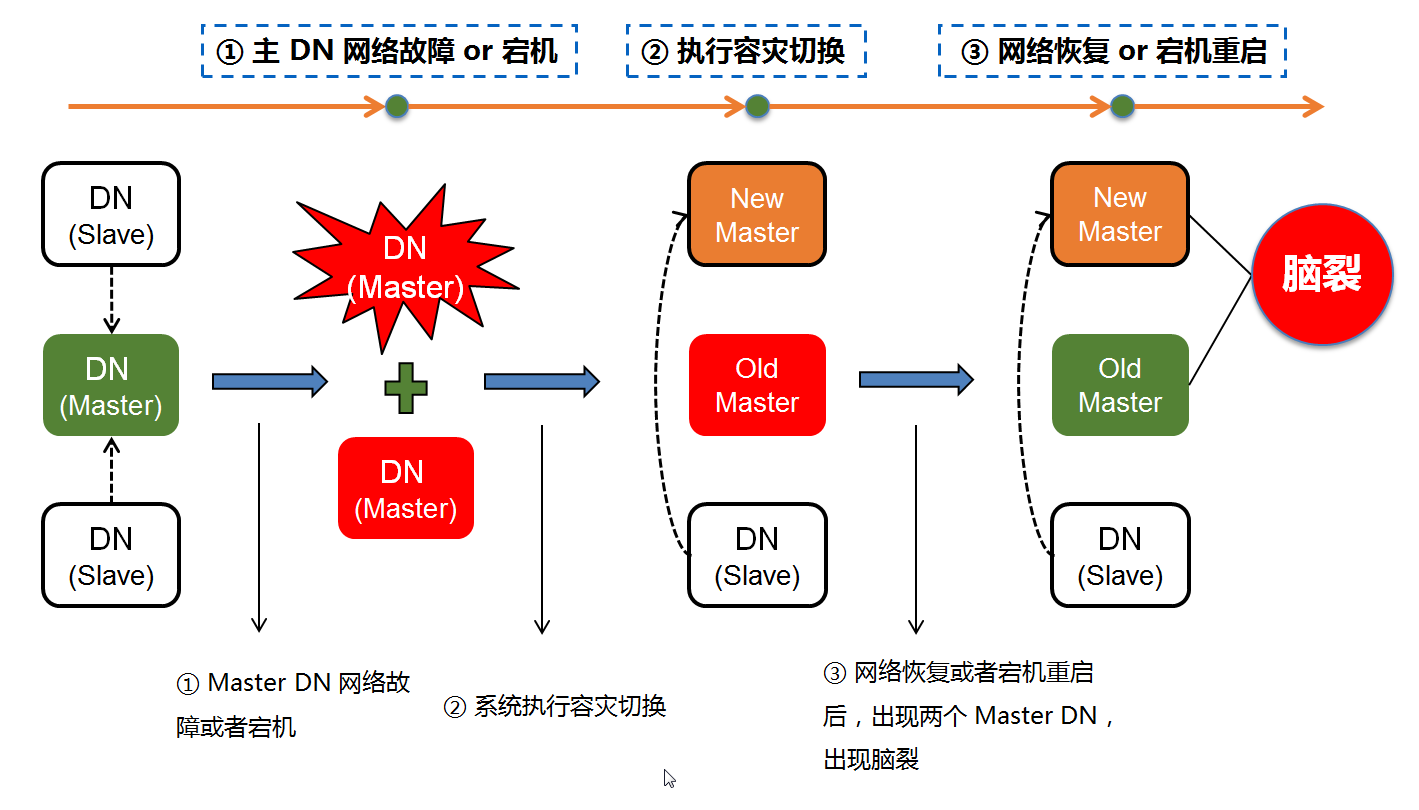
分布式系统容灾中的“脑裂”情况
分布式系统,通常是由若干台物理服务器通过网络搭建而成的,与单机系统不同的是,分布式系统通常由多台设备组成。主机(物理服务器)宕机 或者 网络故障 是大概率事件,而 脑裂 场景则是分布式系统中的常见问题(如下图)。
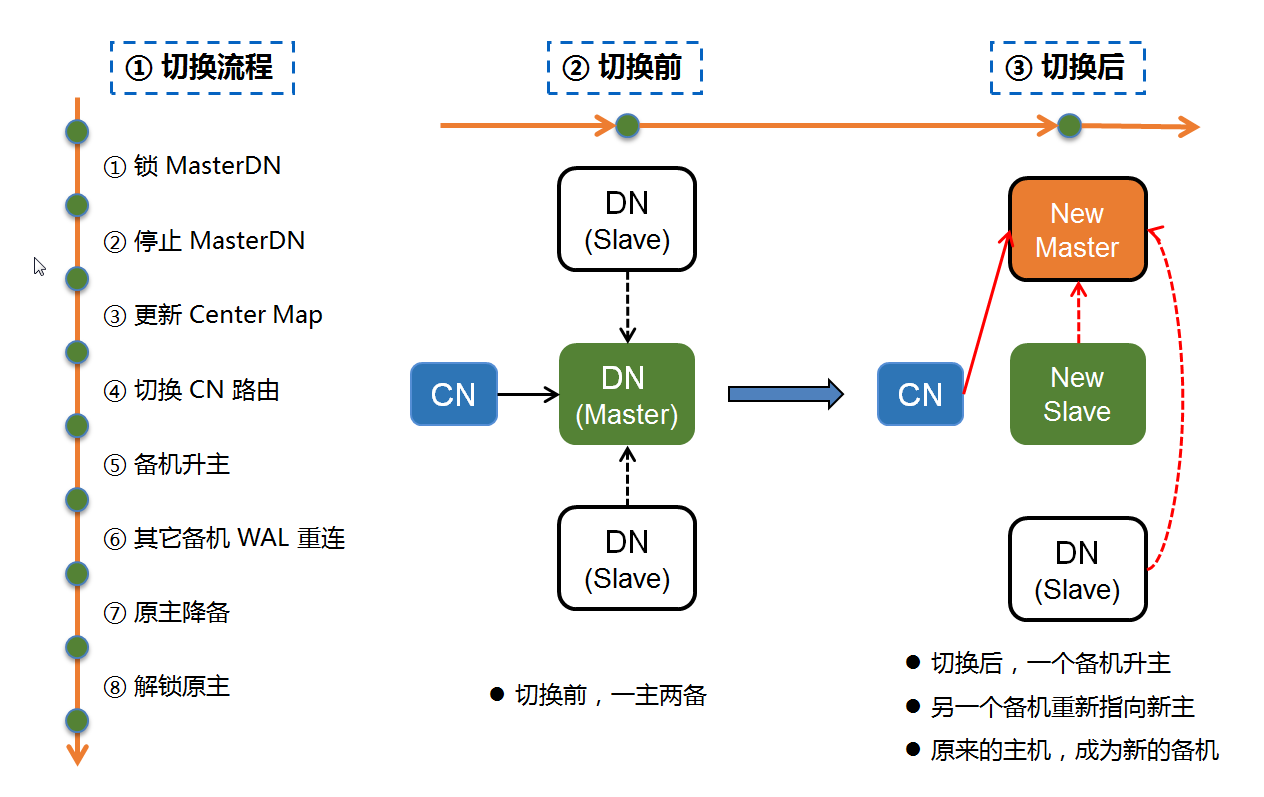
当系统出现节点异常后,为避免脑裂,我们通常需要一个全局的调度集群,出现故障时,通过全局调度集群锁住原Master节点,并通过内部选举,提升某最优Slave节点为Master。到原有故障Master恢复后,在将其降级为Slave重新加入集群,使得系统仍然是一主两备,保障系统始终处于一个高可用的状态。
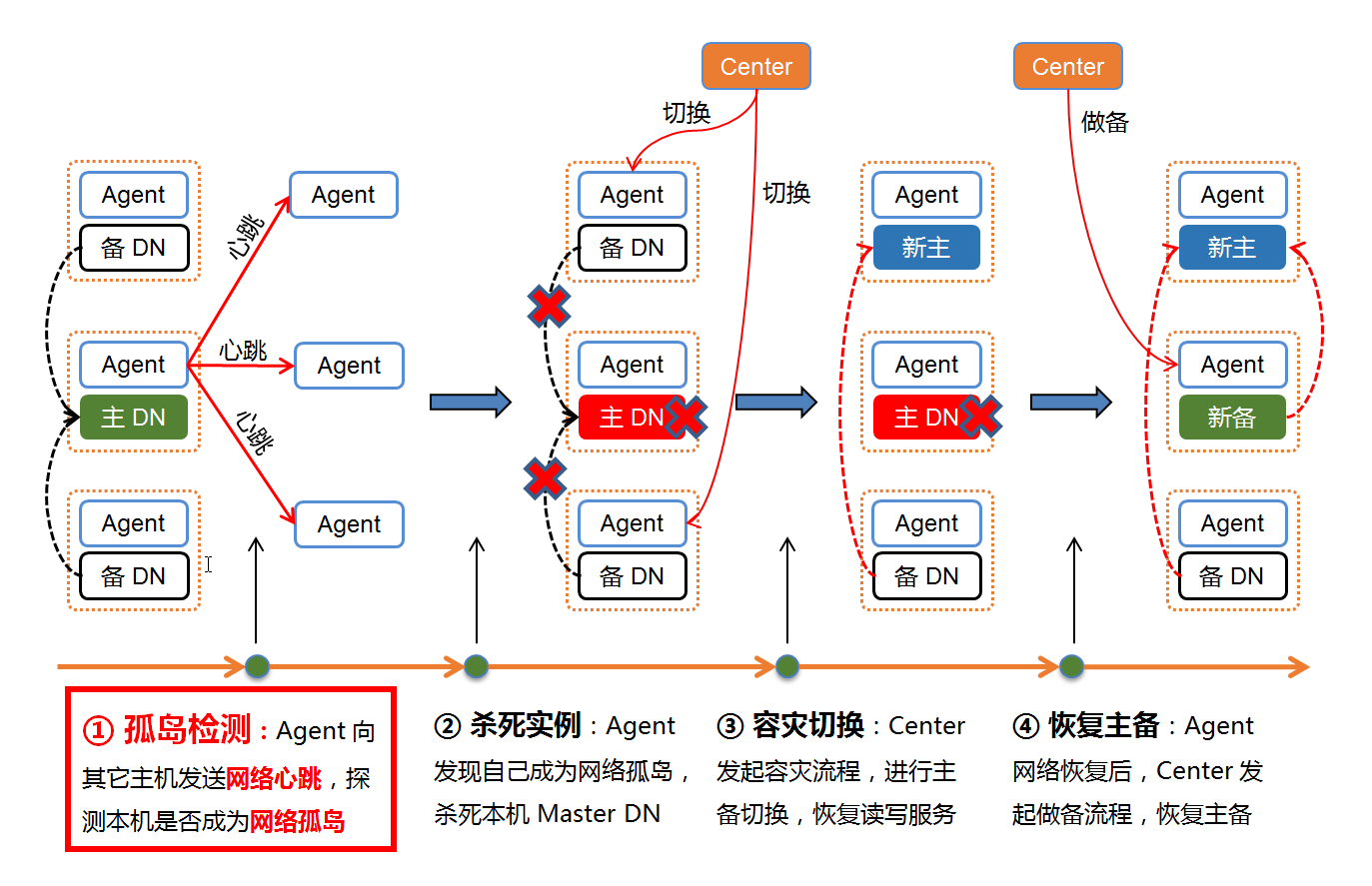
深入到分布式系统调度内部过程,又需要去解决孤岛检测和角色校验两个问题。
- 孤岛检测: 解决由于 Master DN 网络故障恢复后,导致 Master DN 脑裂的问题。
- 角色校验: 解决由于 Master DN 主机宕机重启后,导致 Master DN 脑裂的问题。

分布式系统的某一主机网络故障时,某一个节点就行是没有通讯的孤岛,因此孤岛检测很形象的比喻这种脑裂场景。因此分布式系统通常将孤岛检测拆分为以下几个步骤:
- 检测孤岛:分布式系统通过部署于每个节点的Agent,向集群所有主机发送网络心跳,实时检测连通性。若无法连通Center,意味着自己成为网络孤岛。
- 杀死实例:Agent 发现自己成为网络孤岛后,会主动发起请求杀死本机所有CN/DN实例。
- 容灾切换:Center 监听到集群 Master DN 异常(或无法连通时),主动容灾切换,以恢复数据库服务。由于原Master DN已被Agent杀死,整个系统只有新 Master DN 提供读写服务,因此系统没有 Master DN 脑裂。
- 恢复主备:孤岛主机网络恢复后,Center正常连通Agent后,会向该主机上的 Agent 发起做备指令,让原 Master DN 降级成为一个全新的 Slave DN,以恢复系统一主两备的高可用模式。
通过 Agent 的 孤岛检测 机制,Tbase 在任意 Master DN 网络故障情况下,都能保证系统一直处于高可用的状态。
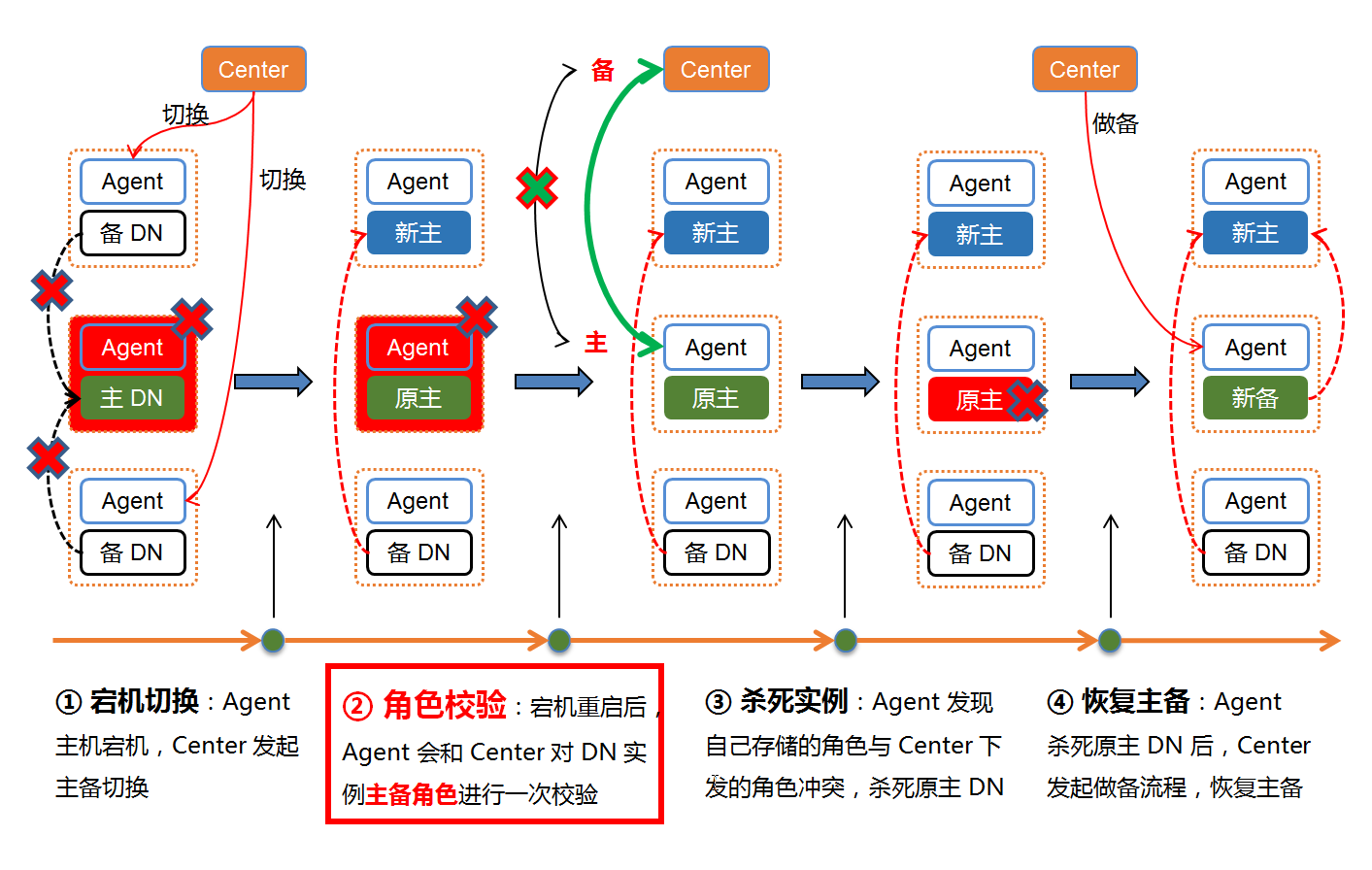
当发生 主机宕机 后,分布式系统就需要 通过 角色校验 机制来解决系统 的脑裂问题,如下图所示,仍然以Tbase举例:
- 宕机切换:当 Master DN 所在主机发生宕机后,Center发起状态仲裁,生成容灾指令,对该主机上的 Master DN 执行容灾切换,容灾切换后,Tbase 系统中的每组 DN 节点都只有唯一的一个 Master DN 对外提供读写服务。
- 角色校验:当故障主机宕机重启后,Agent 和 Center 会通过心跳包对 Agent 所监控的节点执行一次 主备角色校验。由于宕机后,Center 对故障主机上的原 Master DN 执行了容灾切换,因此 Center 认为该主机上的该 DN 节点角色为 Salve DN,但是在容灾切换的过程中,由于原 Master DN 主机因为宕机,无法接收容灾指令,因此宕机重启后,该主机上的 Agent 认为该 DN 节点角色仍然为 Master DN,此时 Agent 和 Center 发生角色校验失败,
- 杀死实例:角色校验失败后,Agent 会杀死本机所有 CN/DN 节点,以防止主机宕机重启后,原 Master DN 和新 Master DN 并存而出现系统脑裂。
- 恢复主备:在 Agent 由于角色校验失败将 CN/DN 杀死后,Center 会向原 Master DN 所在的 Agent 发起做备指令,将原 Master DN 降级成为新的 Slave DN,以恢复系统一主两备的高可用模式。
通过 Agent 和 Center 的 角色校验 机制,Tbase 在任意 Master DN主机宕机重启的情况下,也能保证系统一直处于高可用的状态。
目前,Tbase 已经支持在专有云(私有化)中部署,且很好的兼容PostgreSQL协议,解决了存储成本、数据倾斜、在线扩容、分布式事务、跨节点JOIN等敏感问题,目前Tbase已经在微信支付、电子政务大厅、公安等系统上稳定运行。

最后,欢迎关注我的个人微信公众号:业余草(yyucao)!可加作者微信号:xttblog2。备注:“1”,添加博主微信拉你进微信群。备注错误不会同意好友申请。再次感谢您的关注!后续有精彩内容会第一时间发给您!原创文章投稿请发送至532009913@qq.com邮箱。商务合作也可添加作者微信进行联系!
本文原文出处:业余草: » Tbase腾讯自研全功能分布式关系数据库