
本博客日IP超过2000,PV 3000 左右,急需赞助商。
极客时间所有课程通过我的二维码购买后返现24元微信红包,请加博主新的微信号:xttblog2,之前的微信号好友位已满,备注:返现
受密码保护的文章请关注“业余草”公众号,回复关键字“0”获得密码
所有面试题(java、前端、数据库、springboot等)一网打尽,请关注文末小程序

腾讯云】1核2G5M轻量应用服务器50元首年,高性价比,助您轻松上云
Lucene 近年来越来越火,电商项目基本上都有使用。最近我在优化一些公司内部的系统,其中在搜索模块,我打算使用 Lucene 取代原来的基于 SQL 形式的搜索。本文算是 Lucene中文教程的第一章,认识 Lucene,和它的一些核心类介绍。
在开始之前,我在百度上搜索了 Lucene,发现下面的这些关键词比较火:
ucene和solr的区别 、Lucene面试题、elasticsearch、Lucene netcore、Lucene怎么读、Lucene搜索、Lucene的名字、Lucene Spark、Lucene 原文档。
在谷歌上搜索 Lucene,发现下面这些关键词比较火:
lucene介绍、lucene github、lucene使用、lucene tutorial、lucene教程、lucene elasticsearch、lucene document、lucene solr、lucene中文教程、lucene jar。
经统计后,发现网上还是缺少一些 Lucene 方面的教程资料。而且 Lucene 方面的搜索指数在逐渐增高,因此我想对 Lucene 写一个教程集合,方便大家学习!
相信大多数公司的数据库都需要采用分库分表等一些策略,而对于某些特定的业务需求,分别从不同的库不同的表中去检索特定的数据显得比较繁琐,而Lucene正好可以解决某些特殊需求,对于不同库不同表中的数据先建立全量索引,然后将需要检索的数据写入某个单独的表中,供其它业务需求方查询,以后的每天只需要做增量索引并写入数据表即可。
Lucene是一个高效的,基于Java的全文检索库,生活中数据主要分为两种:结构化数据和非结构化数据。一般使用的XML、JSON、数据库等都是结构化数据,非结构化数据也叫全文数据,而这种全文数据正是Lucene的用武之地。全文检索主要有两个过程,索引创建(Indexing)和搜索索引(Search)。
Lucene 的特点有很多,我从网上找了下面几个方便大家认识:
- 在现代的硬件上一小时可以索引150GB的数据
- 索引20GB的文本文件,产生的索引文件大概是4-6GB
- 只需要1MB的堆内存
- 可定制的排序模型
- 支持多种查询类型
- 通过特定的字段搜索
- 通过特定的字段排序
- 近实时的索引和搜索
- Faceting,Grouping,Highlighting,Suggestions等
基于 Lucene 的搜索技术,产生了两个大家非常熟悉的流行框架:Apache Solr 和 Elastic search。以及一些其他语言对 Lucene 的实现。
Lucene 搜索技术,最重要的部分就是索引。可以说所有的搜索技术都是基于索引的,包括数据库索引。
Lucene 的索引一般是创建并存储在文件系统之上。可以是本地,也可以是远程数据库等。Lucene 在文件系统中存储索引的最基本的抽象实现类是 BaseDirectory,该类继承自 Directory,BaseDirectory 有两个主要的实现类:
- FSDirectory:在文件系统上存储索引文件,有六个子类,如下是三个常用的子类:SimpleFSDirectory、NIOFSDirectory、MMapDirectory。
- RAMDirectory:在内存中暂存索引文件,只对小索引好,大索引会出现频繁GC。
Lucene 里面的索引核心类
- IndexWriter:负责创建索引或打开已有索引
- IndexWriterConfig:持有创建IndexWriter的所有配置项
- Directory:描述了Lucene索引的存放位置,它的子类负责具体指定索引的存储路径
- Analyzer:负责文本分析,从被索引文本文件中提取出语汇单元。对于文本分析器Analyzer,需要注意一点,就是使用哪种Analyzer进行索引创建,查询的时候也要使用哪种Analyzer查询,否则查询结果不正确。
- Document:代表一些域(Field)的集合,你可以将Document对象理解为虚拟文档-例如Web页面、E-mail信息或者文本文件
- Field:索引中的每个文档都包含一个或多个不同命名的域,每个域都有一个域名和对应的域值
- FieldType:描述了Field的各种属性,在不使用某种具体的Field类型(例如StringField,TextField)时需要用到此类
Lucene 的使用场景
- 搜索引擎。例如:百度、必应、谷歌等。
- 站内搜索,比如,我个人网站的站内搜索。
- 文件系统的搜索,例如,window 系统中的搜索等。
- 商品搜索,电商系统的商品搜索。
- 大型系统的分库分表搜索
- 一些软件的内部搜索,例如 Eclipse 中的搜索等。
Lucene 全文检索的流程
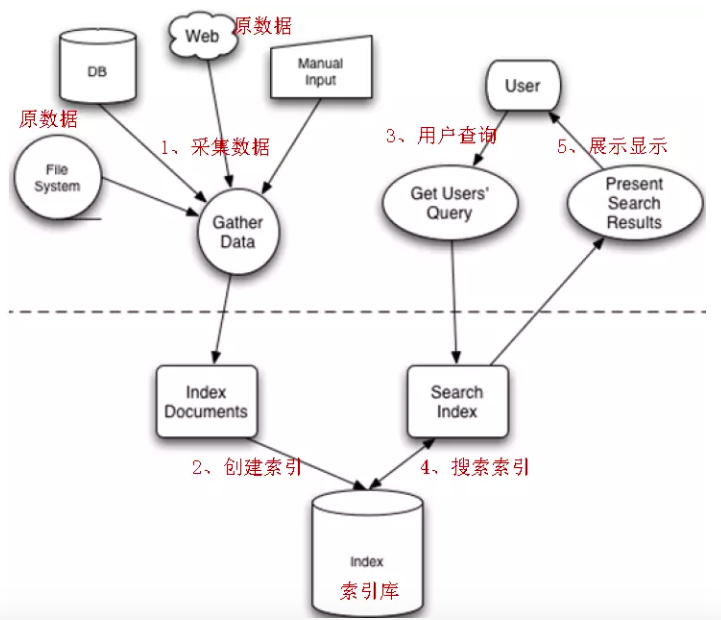
通过本文,希望大家对 Lucene 有一个大概的认识,后面我们继续深入学习 Lucene。

最后,欢迎关注我的个人微信公众号:业余草(yyucao)!可加作者微信号:xttblog2。备注:“1”,添加博主微信拉你进微信群。备注错误不会同意好友申请。再次感谢您的关注!后续有精彩内容会第一时间发给您!原创文章投稿请发送至532009913@qq.com邮箱。商务合作也可添加作者微信进行联系!
本文原文出处:业余草: » Lucene 实战教程第一章 Lucene 简介