
本博客日IP超过2000,PV 3000 左右,急需赞助商。
极客时间所有课程通过我的二维码购买后返现24元微信红包,请加博主新的微信号:xttblog2,之前的微信号好友位已满,备注:返现
受密码保护的文章请关注“业余草”公众号,回复关键字“0”获得密码
所有面试题(java、前端、数据库、springboot等)一网打尽,请关注文末小程序

腾讯云】1核2G5M轻量应用服务器50元首年,高性价比,助您轻松上云
我在前面介绍过,所有的搜索技术大部分都是靠索引来实现,所以索引很重要。于是我就把索引这一块单独的抽取出来作为一章来写。
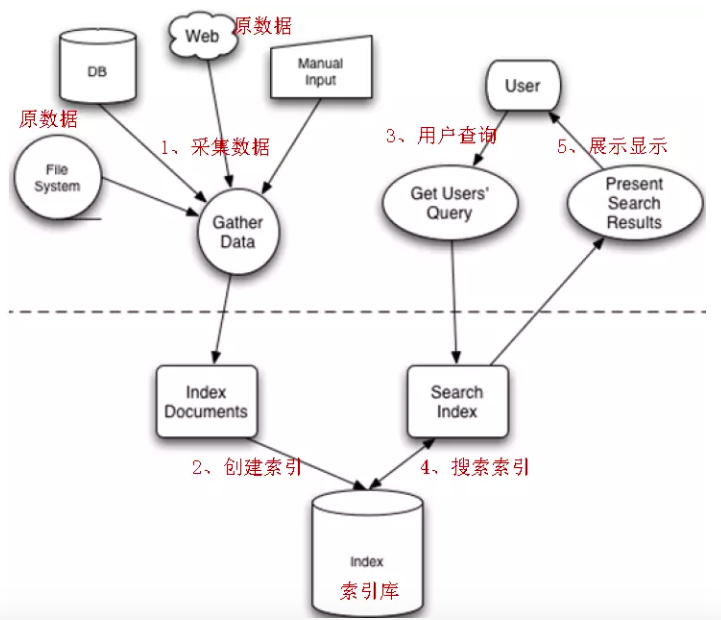
通过上面这张流程图,我们也可以看出索引对于 Lucene 的重要性。
全文检索的流程分为两大部分:索引流程、搜索流程。
- 索引流程:即采集数据–>构建文档对象–>分析文档(分词)–>创建索引。
- 搜索流程:即用户通过搜索界面–>创建查询–>执行搜索,搜索器从索引库搜索–>渲染搜索结果。
Lucene 本身不能进行视图渲染。
创建索引
索引的创建方式有三种,通过 IndexWriterConfig.OpenMode 进行指定,模式有三种,分别是:
- CREATE:创建一个新的索引或者覆写已经存在的索引
- APPEND:打开一个已经存在的索引
- CREATE_OR_APPEND:如果不存在则创建新的索引,如果存在则追加索引
/**
* 创建索引写入器
* @param indexPath
* @param create
* @throws IOException
*/
public IndexWriter getIndexWriter(String indexPath, boolean create) throws IOException {
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(new StandardAnalyzer());
if (create) {
indexWriterConfig.setOpenMode(IndexWriterConfig.OpenMode.CREATE);
} else {
indexWriterConfig.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND);
}
Directory directory = FSDirectory.open(Paths.get(indexPath));
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
return indexWriter;
}
如果仅仅做测试用,还可以将索引文件存储在内存之中,可以使用 RAMDirectory。
public class LuceneDemo {
private Directory directory;
private String[] ids = {"1", "2"};
private String[] unIndex = {"Netherlands", "Italy"};
private String[] unStored = {"Amsterdam has lots of bridges", "Venice has lots of canals"};
private String[] text = {"Amsterdam", "Venice"};
private IndexWriter indexWriter;
private IndexWriterConfig indexWriterConfig = new IndexWriterConfig(new StandardAnalyzer());
@Test
public void createIndex() throws IOException {
directory = new RAMDirectory();
//指定将索引创建信息打印到控制台
indexWriterConfig.setInfoStream(System.out);
indexWriter = new IndexWriter(directory, indexWriterConfig);
indexWriterConfig = (IndexWriterConfig) indexWriter.getConfig();
FieldType fieldType = new FieldType();
fieldType.setIndexOptions(IndexOptions.DOCS_AND_FREQS_AND_POSITIONS);
fieldType.setStored(true);//存储
fieldType.setTokenized(true);//分词
for (int i = 0; i < ids.length; i++) {
Document document = new Document();
document.add(new Field("id", ids[i], fieldType));
document.add(new Field("country", unIndex[i], fieldType));
document.add(new Field("contents", unStored[i], fieldType));
document.add(new Field("city", text[i], fieldType));
indexWriter.addDocument(document);
}
indexWriter.commit();
}
}
在 6.x 的版本中,调用 IndexWriter 的 close() 方法时会自动调用 commit() 方法,在调用 commit() 方法时会自动调用 flush() 方法。所以一般直接调用 commit 即可。不需要做类似下面的操作:
indexWriter.flush(); indexWriter.commit(); indexWriter.close();
总结一下索引的创建流程:
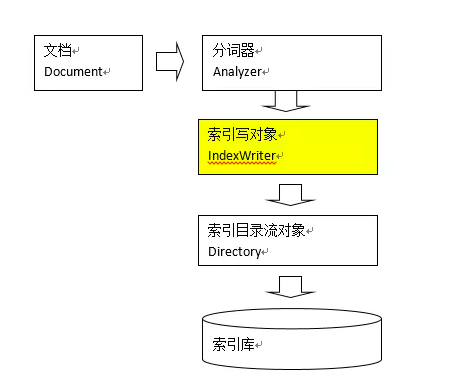
IndexWriter 是索引过程的核心组件,通过 IndexWriter 可以创建新索引、更新索引、删除索引操作。IndexWriter 需要通过 Directory对索引进行存储操作。
Directory 描述了索引的存储位置,底层封装了 I/O 操作,负责对索引进行存储。它是一个抽象类,它的子类常用的包括 FSDirectory(在文件系统存储索引)、RAMDirectory(在内存存储索引)。
下面看一个从数据库中查询数据,创建索引的例子:
@Test
public void createIndex() throws Exception {
// 采集数据
BookDao dao = new BookDaoImpl();
List<Book> list = dao.queryBooks();
// 将采集到的数据封装到Document对象中
List<Document> docList = new ArrayList<>();
Document document;
for (Book book : list) {
document = new Document();
// store:如果是yes,则说明存储到文档域中
// 图书ID
// 不分词、索引、存储 StringField
Field id = new StringField("id", book.getId().toString(), Store.YES);
// 图书名称
// 分词、索引、存储 TextField
Field name = new TextField("name", book.getName(), Store.YES);
// 图书价格
// 分词、索引、存储 但是是数字类型,所以使用FloatField
Field price = new FloatField("price", book.getPrice(), Store.YES);
// 图书图片地址
// 不分词、不索引、存储 StoredField
Field pic = new StoredField("pic", book.getPic());
// 图书描述
// 分词、索引、不存储 TextField
Field description = new TextField("description",
book.getDescription(), Store.NO);
// 设置boost值
if (book.getId() == 4)
description.setBoost(100f);
// 将field域设置到Document对象中
document.add(id);
document.add(name);
document.add(price);
document.add(pic);
document.add(description);
docList.add(document);
}
// 创建分词器,标准分词器
// Analyzer analyzer = new StandardAnalyzer();
// 使用ikanalyzer
Analyzer analyzer = new IKAnalyzer();
// 创建IndexWriter
IndexWriterConfig cfg = new IndexWriterConfig(Version.LUCENE_4_10_3,
analyzer);
// 指定索引库的地址
File indexFile = new File("E:\\11-index\\hcx\\");
Directory directory = FSDirectory.open(indexFile);
IndexWriter writer = new IndexWriter(directory, cfg);
// 通过IndexWriter对象将Document写入到索引库中
for (Document doc : docList) {
writer.addDocument(doc);
}
// 关闭writer
writer.close();
}
删除文档
在 IndexWriter 中提供了从索引中删除 Document 的接口,有 3 个接口,分别是:
- deleteDocuments(Query… queries):删除所有匹配到查询语句的Document
- deleteDocuments(Term… terms):删除所有包含有terms的Document
- deleteAll():删除索引中所有的Document
deleteDocuments(Term… terms)方法,只接受 Term 参数,而 Term 只提供如下四个构造函数:
- Term(String fld, BytesRef bytes)
- Term(String fld, BytesRefBuilder bytesBuilder)
- Term(String fld, String text)
- Term(String fld)
所以我们无法使用 deleteDocuments(Term… terms)去删除一些非 String 值的 Field,例如 IntPoint,LongPoint,FloatPoint,DoublePoint等。这时候就需要借助传递 Query 实例的方法去删除包含某些特定类型 Field 的 Document。
@Test
public void testDelete() throws IOException {
RAMDirectory ramDirectory = new RAMDirectory();
IndexWriter indexWriter = new IndexWriter(ramDirectory,
new IndexWriterConfig(new StandardAnalyzer()));
Document document = new Document();
document.add(new IntPoint("ID", 1));
indexWriter.addDocument(document);
indexWriter.commit();
//无法删除ID为1的
indexWriter.deleteDocuments(new Term("ID", "1"));
indexWriter.commit();
DirectoryReader open = DirectoryReader.open(ramDirectory);
IndexSearcher indexSearcher = new IndexSearcher(open);
Query query = IntPoint.newExactQuery("ID", 1);
TopDocs search = indexSearcher.search(query, 10);
//命中,1,说明并未删除
System.out.println(search.totalHits);
//使用Query删除
indexWriter.deleteDocuments(query);
indexWriter.commit();
indexSearcher = new IndexSearcher(DirectoryReader.openIfChanged(open));
search = indexSearcher.search(query, 10);
//未命中,0,说明已经删除
System.out.println(search.totalHits);
}
关于索引我就先写到这里,后面我们继续学习 Field 相关的属性及排序操作。

最后,欢迎关注我的个人微信公众号:业余草(yyucao)!可加作者微信号:xttblog2。备注:“1”,添加博主微信拉你进微信群。备注错误不会同意好友申请。再次感谢您的关注!后续有精彩内容会第一时间发给您!原创文章投稿请发送至532009913@qq.com邮箱。商务合作也可添加作者微信进行联系!
本文原文出处:业余草: » Lucene 实战教程第三章创建索引 IndexWriter