
本博客日IP超过2000,PV 3000 左右,急需赞助商。
极客时间所有课程通过我的二维码购买后返现24元微信红包,请加博主新的微信号:xttblog2,之前的微信号好友位已满,备注:返现
受密码保护的文章请关注“业余草”公众号,回复关键字“0”获得密码
所有面试题(java、前端、数据库、springboot等)一网打尽,请关注文末小程序

【腾讯云】1核2G5M轻量应用服务器50元首年,高性价比,助您轻松上云
最近在学习 Drools 规则引擎框架,其中涉及到 Rete 算法。并对 Rete 算法做了一些研究,要不然在你找新工作面试时,问你会 Drools 规则引擎框架吗?你说会!然后面试官接着问你,你了解 Rete 算法吗?你说听说过。然后面试官再问你,你知道 Rete 算法的原理吗?你能实现 Rete 算法吗?
追问了这么多,你可能就回答不上来了。面试官最喜欢做的就是追着一直问,直到你回答不出来为止。从追问的过程中,了解你的技术能力以及学习能力。阿里的面试官就是这种类型的,追问到底。
为了找一份好工作,或者比你的同事拿更高的薪水,就要不仅会用,还有会它的原理以及实现。正是基于此,本文将详细介绍 Rete 算法。
RETE 算法简介
Rete算法是一种前向规则快速匹配算法,其匹配速度与规则数目无关。Rete是拉丁文,对应英文是net,也就是网络。Rete算法通过形成一个rete网络进行模式匹配,利用基于规则的系统的两个特征,即时间冗余性(Temporal redundancy)和结构相似性(structural similarity),提高系统模式匹配效率。
单词‘Rete’来自拉丁文的网一词,发音为 ri tiorree-tee。
RETE算法是一个用于产生式系统的高效模式匹配算法。在一个产生式系统中,被处理的数据叫做working memory,用于判定的规则分为两个部分LHS(left-hand-side)和RHS(right hand side),分别表示前提和结论。
RETE 算法主要流程
RETE 算法主要流程可以分为以下步骤:
- Match:找出符合LHS部分的working memory集合
- Confilict resolution:选出一个条件被满足的规则
- Act:执行RHS的内容
- 返回第一步
RETE算法主要改进Match的处理过程,通过构建一个网络进行匹配。
RETE 算法详细描述
RETE网络主要分为两个部分,alpha网络和beta网络。如下图所示(图片引用其他网站)。

- alpha网络:过滤working memory,找出符合规则中每一个模式的集合,生成alpha memory(满足该模式的集合)。有两种类型的节点,过滤type的节点和其他条件过滤的节点。
- Beta网络:有两种类型的节点Beta Memory和Join Node。前者主要存储Join完成后的集合。后者包含两个输入口,分别输入需要匹配的两个集合,由Join节点做合并工作传输给下一个节点。
匹配过程描述
- 导入需要处理的事实到facts集合中。
- 如果facts不为空,选择一个fact进行处理。否则停止匹配过程。
- 选择alpha网的第一个节点运行(建立网络的时候设定的),通过该节点则进入alpha网的下一个节点,直到进入alpha memory。否则跳转到下一条判断路径
- 将alpha memory的结果加入到beta memory中,如果不为Terminal节点,则检测另一个输入集合中是否存在满足条件的事实,满足则执行join,进入到下一个beta memory重复执行3。若另一个输入集合无满足条件的事实,返回到2。如果该节点为Terminal节点,执行ACT并添加到facts中。
下面再看一个匹配例子。
规则内容如下:
IF:
年级是三年级以上,
性别是男的,
年龄小于10岁,
身体健壮,
身高170cm以上,
THEN: 这个男孩是一个篮球苗子,需要培养
规则编译网络和匹配过程
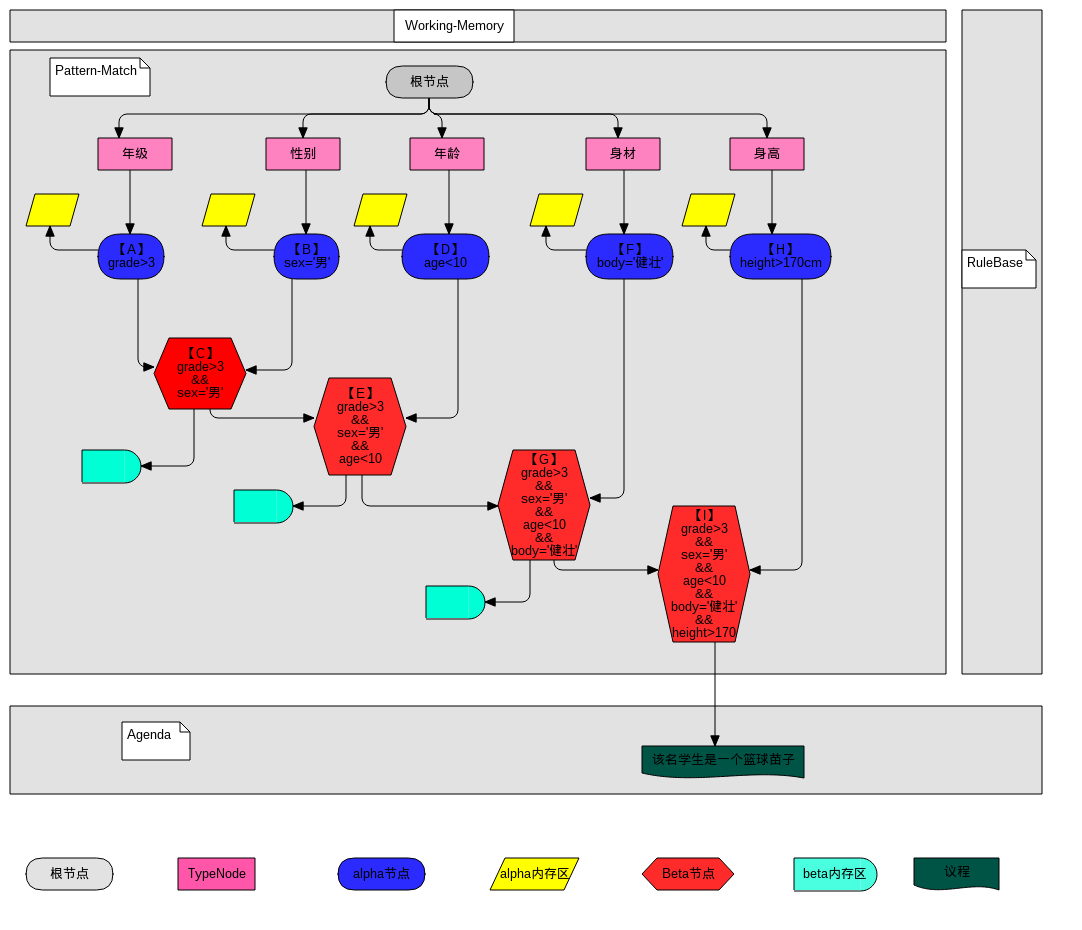
匹配过程:
-
匹配过程中事实在网络节点中的流转顺序为A–>B–>C–>D–>E–>F–>G–>H–>I—>规则匹配通过
-
从working-Memory中拿出一个待匹配的StudentFact对象,进入根节点然后进行匹配,以下是fact在各个节点中的活动图
-
A节点:拿StudentFact的年级数值进行年级匹配,如果年级符合条件,则把该StudentFact的引用记录到A节点的alpha内存区中,退出年级匹配。
-
B节点:拿StudentFact的性别内容进行性别匹配,如果性别符合条件,则把该StudentFact的引用记录到B节点的alpha内存区中,然后找到B节点左引用的Beta节点,也就是C节点。
-
C节点:C节点找到自己的左引用也就是A节点,看看A节点的alpha内存区中是否存放了StudentFact的引用,如果存放,说明年级和性别两个条件都符合,则在C节点的Beta内存区中存放StudentFact的引用,退出性别匹配。
-
D节点:拿StudentFact的年龄数值进行年龄条件匹配,如果年龄符合条件,则把该StudentFact的引用记录到D节点的alpha的内存区中,然后找到D节点的左引用的Beta节点,也就是E节点。
-
E节点:E节点找到自己的左引用也就是C节点,看看C节点的Beta内存区中是否存放了StudentFact的引用,如果存放,说明年级,性别,年龄三个条件符合,则在E节点的Beta内存区中存放StudentFact的引用,退出年龄匹配。
-
F节点:拿StudentFact的身体数值进行身体条件匹配,如果身体条件符合,则把该StudentFact的引用记录到D节点的alpha的内存区中,然后找到F节点的左引用的Beta节点,也就是G节点。
-
G节点:G节点找到自己的左引用也就是E节点,看看E节点的Beta内存区中是否存放了StudentFact的引用,如果存放,说明年级,性别,年龄,身体四个条件符合,则在G节点的Beta内存区中存放StudentFact的引用,退出身体匹配
-
H节点:拿StudentFact的身高数值进行身高条件匹配,如果身高条件符合,则把该StudentFact的引用记录到H节点的alpha的内存区中,然后找到H节点的左引用的Beta节点,也就是I节点。
-
I节点:I节点找到自己的左引用也就是G节点,看看G节点的Beta内存区中是否存放了StudentFact的引用,如果存放了,说明年级,性别,年龄,身体,身高五个条件都符合,则在I节点的Beta内存区中存放StudentFact引用。同时说明该StudentFact对象匹配了该规则,形成一个议程,加入到冲突区,执行该条件的结果部分:该学生是一个篮球苗子。
相关概念
1 事实(fact):
事实:对象之间及对象属性之间的多元关系。为简单起见,事实用一个三元组来表示:(identifier ^attribute value),例如如下事实:
w1:(B1 ^ on B2) w6:(B2 ^color blue)
w2:(B1 ^ on B3) w7:(B3 ^left-of B4)
w3:(B1 ^ color red) w8:(B3 ^on table)
w4:(B2 ^on table) w9:(B3 ^color red)
w5:(B2 ^left-of B3)
2 规则(rule):
由条件和结论构成的推理语句,当存在事实满足条件时,相应结论被激活。一条规则的一般形式如下:
(name-of-this-production
LHS /*one or more conditions*/
–>
RHS /*one or more actions*/
)
其中LHS为条件部分,RHS为结论部分。
下面为一条规则的例子:
(find-stack-of-two-blocks-to-the-left-of-a-red-block
(^on)
(^left-of)
(^color red)
–>
…RHS…
)
3 模式(patten):
模式:规则的IF部分,已知事实的泛化形式,未实例化的多元关系。
(^on)
(^left-of)
(^color red)
模式匹配的一般算法
规则主要由两部分组成:条件和结论,条件部分也称为左端(记为LHS, left-hand side),结论部分也称为右端(记为RHS, right-hand side)。为分析方便,假设系统中有N条规则,每个规则的条件部分平均有P个模式,工作内存中有M个事实,事实可以理解为需要处理的数据对象。
规则匹配,就是对每一个规则r, 判断当前的事实o是否使LHS(r)=True,如果是,就把规则r的实例r(o)加到冲突集当中。所谓规则r的实例就是用数据对象o的值代替规则r的相应参数,即绑定了数据对象o的规则r。
规则匹配的一般算法:
1) 从N条规则中取出一条r;
2) 从M个事实中取出P个事实的一个组合c;
3) 用c测试LHS(r),如果LHS(r(c))=True,将RHS(r(c))加入冲突集中;
4) 取出下一个组合c,goto 3;
5) 取出下一条规则r,goto 2;
RETE算法
Rete算法的编译结果是规则集对应的Rete网络,如下图。Rete网络是一个事实可以在其中流动的图。Rete网络的节点可以分为四类:根节点(root)、类型节点(typenode)、alpha节点、beta节点。其中,根结点是一个虚拟节点,是构建rete网络的入口。类型节点中存储事实的各种类型,各个事实从对应的类型节点进入rete网络。
1 建立rete网络
Rete网络的编译算法如下:
1) 创建根;
2) 加入规则1(Alpha节点从1开始,Beta节点从2开始);
a. 取出模式1,检查模式中的参数类型,如果是新类型,则加入一个类型节点;
b. 检查模式1对应的Alpha节点是否已存在,如果存在则记录下节点位置,如果没有则将模式1作为一个Alpha节点加入到网络中,同时根据Alpha节点的模式建立Alpha内存表;
c. 重复b直到所有的模式处理完毕;
d. 组合Beta节点,按照如下方式:
Beta(2)左输入节点为Alpha(1),右输入节点为Alpha(2)
Beta(i)左输入节点为Beta(i-1),右输入节点为Alpha(i) i>2
并将两个父节点的内存表内联成为自己的内存表;
e. 重复d直到所有的Beta节点处理完毕;
f. 将动作(Then部分)封装成叶节点(Action节点)作为Beta(n)的输出节点;
3) 重复2)直到所有规则处理完毕;
可以把rete算法类比到关系型数据库操作。
把事实集合看作一个关系,每条规则看作一个查询,将每个事实绑定到每个模式上的操作看作一个Select操作,记一条规则为P,规则中的模式为c1,c2,…,ci, Select操作的结果记为r(ci),则规则P的匹配即为r(c1)◇r(c2)◇…◇(rci)。其中◇表示关系的连接(Join)操作。
2 使用rete网络进行匹配
使用一个rete的过程:
1) 对于每个事实,通过select 操作进行过滤,使事实沿着rete网达到合适的alpha节点。
2) 对于收到的每一个事实的alpha节点,用Project(投影操作)将那些适当的变量绑定分离出来。使各个新的变量绑定集沿rete网到达适当的bete节点。
3) 对于收到新的变量绑定的beta节点,使用Project操作产生新的绑定集,使这些新的变量绑定沿rete网络至下一个beta节点以至最后的Project。
4) 对于每条规则,用project操作将结论实例化所需的绑定分离出来。
下面为的图示显示了连接(Join)操作和投影(Project)的执行过程。
3 Rete算法的特点
Rete算法有两个特点使其优于传统的模式匹配算法。
1、状态保存
事实集合中的每次变化,其匹配后的状态都被保存再alpha和beta节点中。在下一次事实集合发生变化时,绝大多数的结果都不需要变化,rete算法通过保存操作过程中的状态,避免了大量的重复计算。Rete算法主要是为那些事实集合变化不大的系统设计的,当每次事实集合的变化非常剧烈时,rete的状态保存算法效果并不理想。
2、节点共享
另一个特点就是不同规则之间含有相同的模式,从而可以共享同一个节点。Rete网络的各个部分包含各种不同的节点共享。

最后,欢迎关注我的个人微信公众号:业余草(yyucao)!可加作者微信号:xttblog2。备注:“1”,添加博主微信拉你进微信群。备注错误不会同意好友申请。再次感谢您的关注!后续有精彩内容会第一时间发给您!原创文章投稿请发送至532009913@qq.com邮箱。商务合作也可添加作者微信进行联系!
本文原文出处:业余草: » Rete 算法原理及实现