
本博客日IP超过2000,PV 3000 左右,急需赞助商。
极客时间所有课程通过我的二维码购买后返现24元微信红包,请加博主新的微信号:xttblog2,之前的微信号好友位已满,备注:返现
受密码保护的文章请关注“业余草”公众号,回复关键字“0”获得密码
所有面试题(java、前端、数据库、springboot等)一网打尽,请关注文末小程序

【腾讯云】1核2G5M轻量应用服务器50元首年,高性价比,助您轻松上云
JavaWeb+Servlet+JSP实现基于物品的协同过滤算法(itemCF)的推荐系统!
今天给大家推荐一个简单的 Java Web推荐系统,主要算法是基于协同过滤算法(itemCF)。
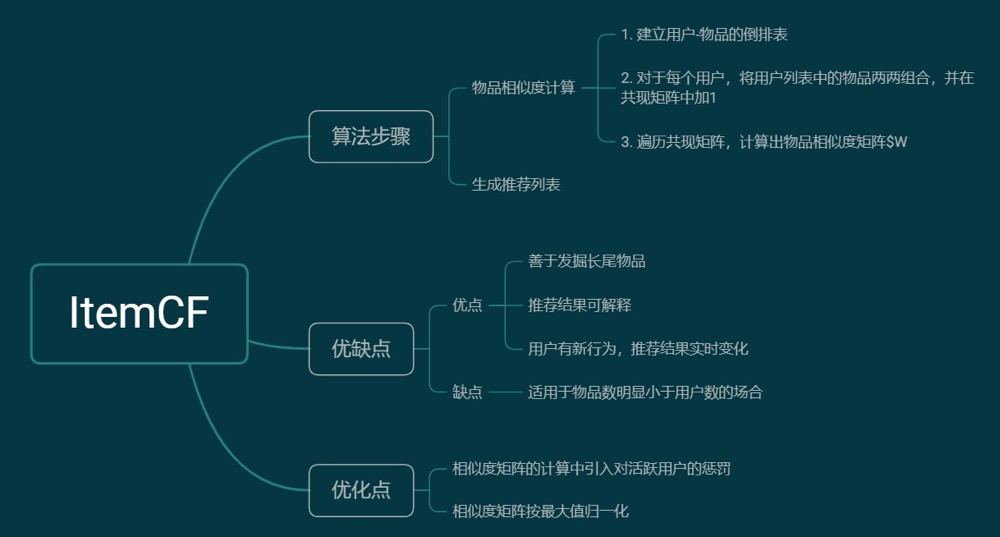
1、 ItemCF算法原理:
ItemCF算法并不利用物品的内容属性计算物品之间的相似度,它主要通过分析用户的行为记录计算物品之间的相似度。该算法认为一个人的兴趣都局限在几个方面,当很多人都对两个物品感兴趣时,就认为这两个物品具有较大的相似度,即物品A,B具有很大的相似度是因为喜欢物品A的用户大都也喜欢物品B。
2、 ItemCF算法步骤:
- 计算物品之间的相似度
- 根据物品的相似度和用户的历史行为给用户生成推荐列表。
2.1 物品相似度计算
- 建立用户-物品的倒排表
- 对于每个用户,将用户列表中的物品两两组合,并在共现矩阵中加1
- 遍历共现矩阵,计算出物品相似度矩阵 W W W,计算公式如下:
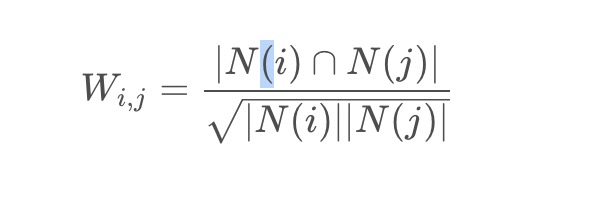
2.2 生成推荐列表
通过如下公式计算用户u对一个物品j的兴趣 :
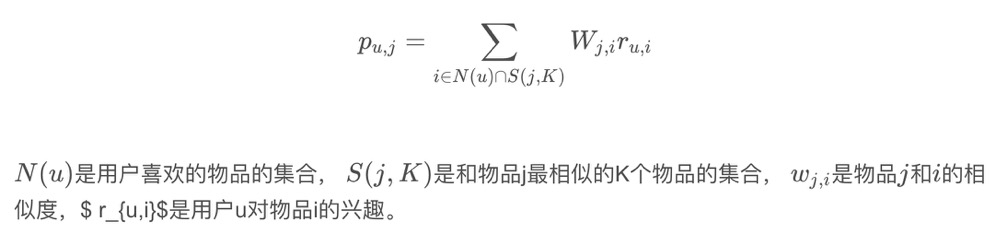
3、ItemCF的优缺点
优点:
- 推荐结果中长尾物品丰富,适用于用户个性化需求强烈的领域
- 可以利用用户的历史行为给推荐结果做出解释
- 用户有新行为,就会实时导致推荐结果的实时变化
缺点:
- 适用于物品数明显小于用户数的场合;如果物品很多,计算物品的相似度矩阵代价很大
4、优化点
- 相似度矩阵的计算中引入对活跃用户的惩罚(活跃用户对物品相似度的贡献应该小于不活跃的用户 ),增加IUF参数来修正物品相似度的计算公式
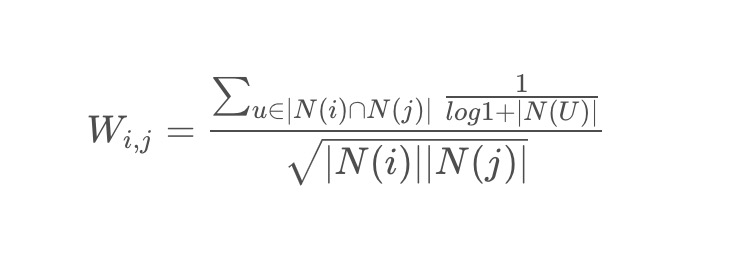
- 对于过于活跃的用户,往往忽略他们的兴趣列表。
- 将ItemCF的相似度矩阵按最大值归一化,可以提高推荐的准确率和覆盖率
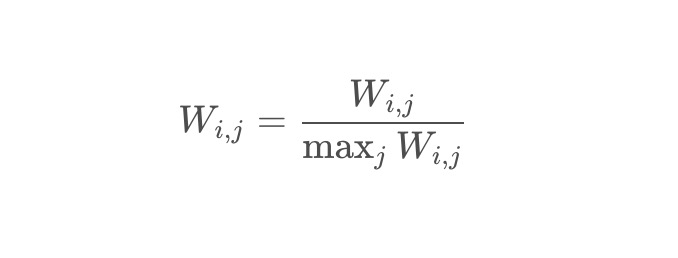
实战
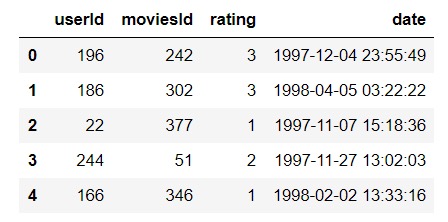
下面代码使用了电影评分数据集,该数据集可以从https://pan.baidu.com/s/1dEeF5dt6zRFpH1u7Rn6JLA下载(提取码:7k1w )。数据中包含了943个用户对1682个电影的10W条评分数据,数据已经处理成csv格式,可通过pandas.read_csv直接读取。
import numpy as np
import pandas as pd
from itertools import combinations, permutations
from operator import itemgetter
def trans_df2dict(df):
"""将数据转化成字典格式"""
user_rating = dict() # 用户评分数据
for row in df.values:
uesr_id, movie_id, rating = row[0], row[1], row[2]
if uesr_id not in user_rating.keys():
user_rating[uesr_id] = {}
user_rating[uesr_id][movie_id] = rating
return user_rating
def get_items_similarity(df, item_num):
"""计算items相似性矩阵,返回相似性矩阵"""
# 1. 建立用户-物品的倒排表
inverted_table = df.groupby(by='userId')['moviesId'].agg(list).to_dict()
# 2. 初始化共现矩阵,遍历每个用户,将物品两两组合,并在共现矩阵中加1
W = np.zeros((item_num, item_num))
# 统计每个电影被多少人看过
count_item_users_num = df.groupby(by='moviesId')['userId'].agg('count').to_dict()
for key, val in inverted_table.items():
val.sort(reverse=True) # 降序
for per in combinations(val, 2):
W[per[0] - 1][per[1] - 1] += 1
W[per[1] - 1][per[0] - 1] += 1
# 计算相似性
for i in range(W.shape[0]):
for j in range(W.shape[1]):
W[i][j] /= np.sqrt(count_item_users_num.get(i + 1) * count_item_users_num.get(j + 1))
w_dict = {}
for i in range(W.shape[0]):
tmp = []
for index, k in enumerate(W[i]):
tmp.append((index + 1, k))
w_dict[i + 1] = tmp
return w_dict
def user_interest_with_items(user_id, item_id, K, user_rating, w_dict):
"""计算指定用户与指定物品的兴趣程度"""
interest = 0
for i in sorted(w_dict[item_id], key=itemgetter(1), reverse=True)[0:K]:
item_index = i[0]
item_simi = i[1]
if item_index in user_rating[user_id].keys():
interest += item_simi * user_rating[user_id][item_index]
return interest
def get_user_interest_list(user_id, K, user_rating, w_dict):
"""计算用户的兴趣列表"""
rank = []
item_id_list = w_dict.keys()
for item_id in item_id_list:
if item_id in user_rating[user_id].keys():
continue
interest = user_interest_with_items(user_id, item_id, K, user_rating, w_dict)
rank.append((item_id, interest))
return sorted(rank, key=itemgetter(1), reverse=True)
if __name__ == '__main__':
df = pd.read_csv('./ml-100k.csv')
item_num = df.moviesId.nunique()
user_num = df.userId.nunique()
user_rating = trans_df2dict(df)
w_dict = get_items_similarity(df, item_num)
recommend_list = get_user_interest_list(2, 20, user_rating, w_dict)
print(recommend_list[0:20])输出的前20个推荐的电影ID:

基于上面的原理和理论以及 Python 的实战。我这里又用 Java 实现了一个简单的 Web推荐系统。
本项目的数据存储在 MySQL 中,项目源码中整理了 SQL 文件。
项目整体结构包括:登录页面、注册页面、推荐列表等。是一个简单的 idea + Tomcat 的上手项目,有需要的可以加我微信:xttblog2,免费送给大家!

最后,欢迎关注我的个人微信公众号:业余草(yyucao)!可加作者微信号:xttblog2。备注:“1”,添加博主微信拉你进微信群。备注错误不会同意好友申请。再次感谢您的关注!后续有精彩内容会第一时间发给您!原创文章投稿请发送至532009913@qq.com邮箱。商务合作也可添加作者微信进行联系!
本文原文出处:业余草: » JavaWeb+Servlet+JSP实现基于物品的协同过滤算法(itemCF)的推荐系统!