
本博客日IP超过2000,PV 3000 左右,急需赞助商。
极客时间所有课程通过我的二维码购买后返现24元微信红包,请加博主新的微信号:xttblog2,之前的微信号好友位已满,备注:返现
受密码保护的文章请关注“业余草”公众号,回复关键字“0”获得密码
所有面试题(java、前端、数据库、springboot等)一网打尽,请关注文末小程序

【腾讯云】1核2G5M轻量应用服务器50元首年,高性价比,助您轻松上云
IO多路复用、select模型、poll模型、epoll模型等知识点,常常是Java高级工程师及以上岗位在面试中遇到的必问面试题,今天乘着放假休息,我们一起来搞懂他们。
为了讲多路复用,当然还是要跟风,采用鞭尸的思路,先讲讲传统的网络 IO 的弊端,用拉踩的方式捧起多路复用 IO 的优势。
为了方便理解,以下所有代码都是伪代码,知道其表达的意思即可。
阻塞 IO
服务端为了处理客户端的连接和请求的数据,写了如下代码。
listenfd = socket(); // 打开一个网络通信端口
bind(listenfd); // 绑定
listen(listenfd); // 监听
while(1) {
connfd = accept(listenfd); // 阻塞建立连接
int n = read(connfd, buf); // 阻塞读数据
doSomeThing(buf); // 利用读到的数据做些什么
close(connfd); // 关闭连接,循环等待下一个连接
}这段代码会执行得磕磕绊绊,就像这样。

可以看到,服务端的线程阻塞在了两个地方,一个是 accept 函数,一个是 read 函数。
如果再把 read 函数的细节展开,我们会发现其阻塞在了两个阶段。
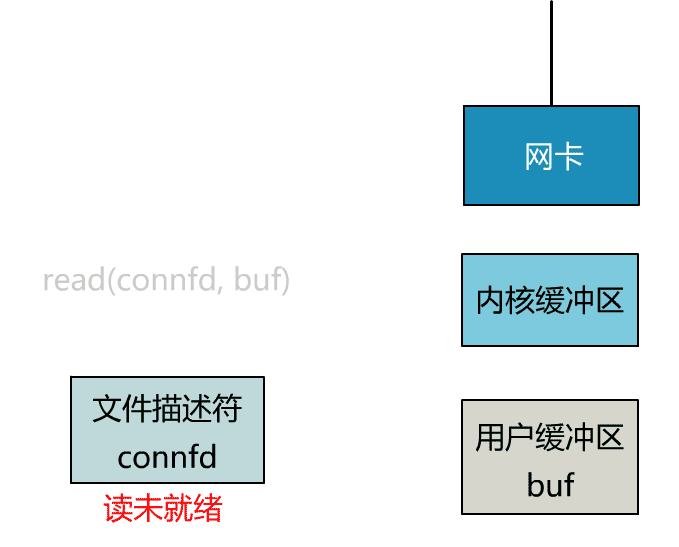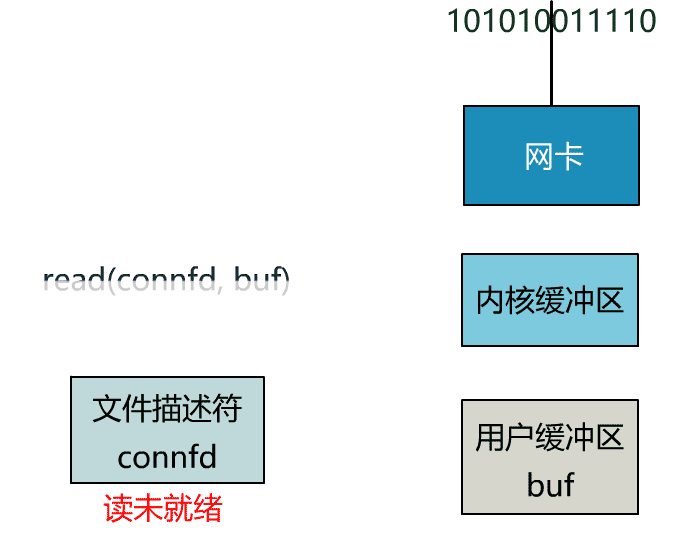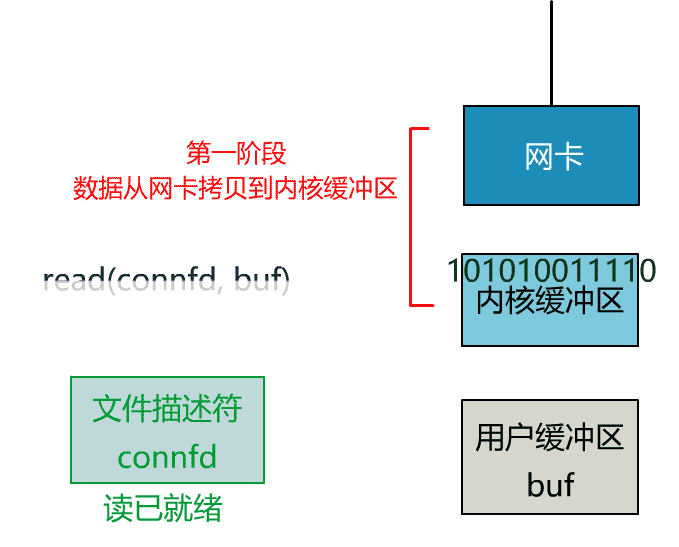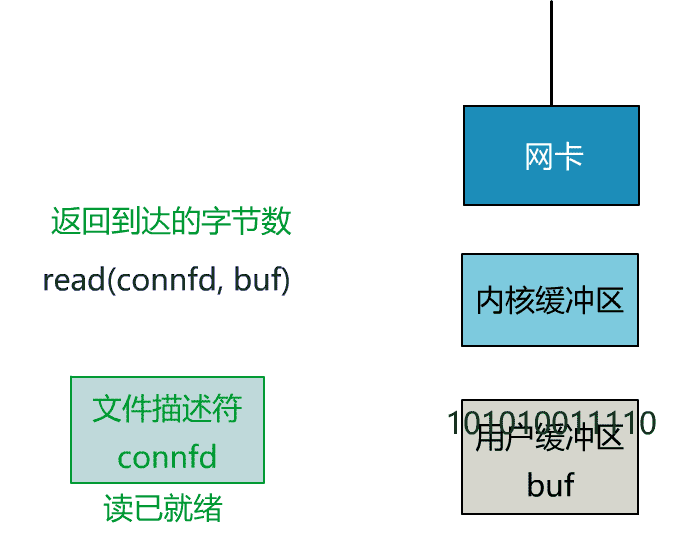
这就是传统的阻塞 IO。
整体流程如下图。
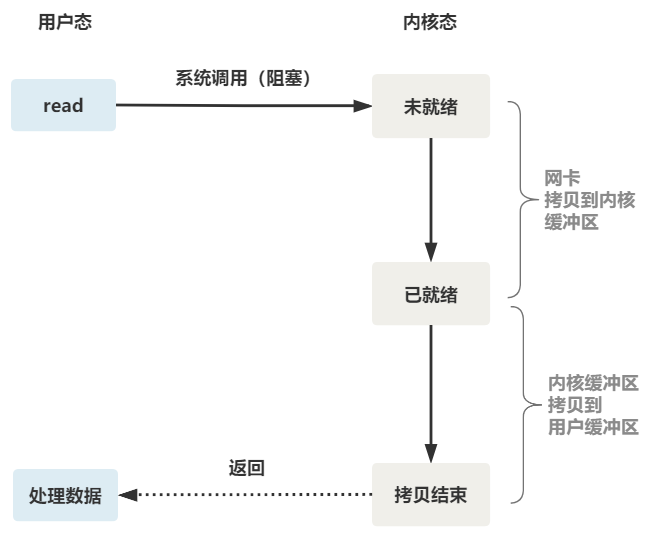
所以,如果这个连接的客户端一直不发数据,那么服务端线程将会一直阻塞在 read 函数上不返回,也无法接受其他客户端连接。
这肯定是不行的。
非阻塞 IO
为了解决上面的问题,其关键在于改造这个 read 函数。
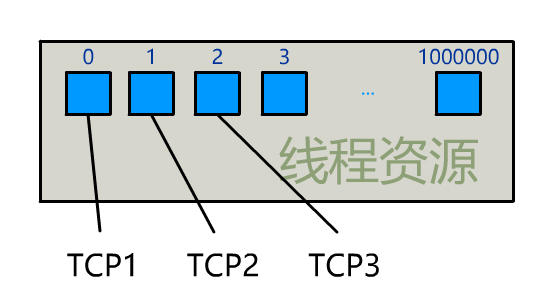
有一种聪明的办法是,每次都创建一个新的进程或线程,去调用 read 函数,并做业务处理。
while(1) {
connfd = accept(listenfd); // 阻塞建立连接
pthread_create(doWork); // 创建一个新的线程
}
void doWork() {
int n = read(connfd, buf); // 阻塞读数据
doSomeThing(buf); // 利用读到的数据做些什么
close(connfd); // 关闭连接,循环等待下一个连接
}这样,当给一个客户端建立好连接后,就可以立刻等待新的客户端连接,而不用阻塞在原客户端的 read 请求上。

不过,这不叫非阻塞 IO,只不过用了多线程的手段使得主线程没有卡在 read 函数上不往下走罢了。操作系统为我们提供的 read 函数仍然是阻塞的。
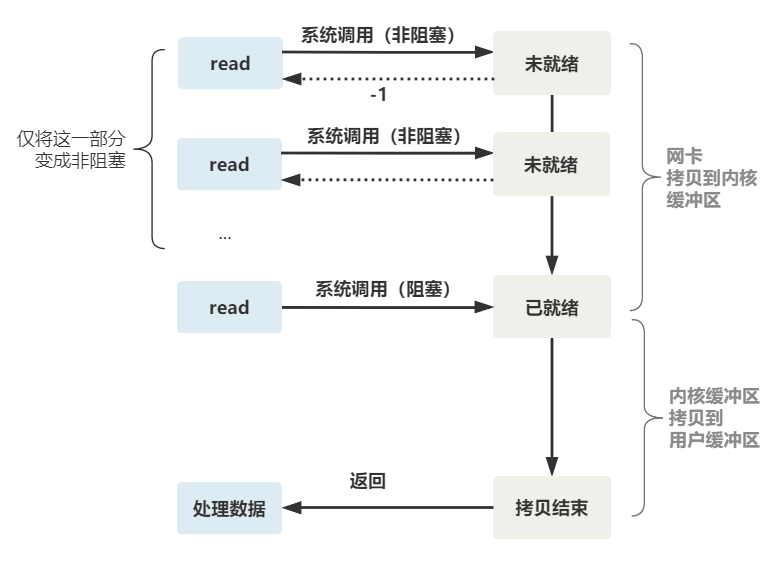
所以真正的非阻塞 IO,不能是通过我们用户层的小把戏,而是要恳请操作系统为我们提供一个非阻塞的 read 函数。
这个 read 函数的效果是,如果没有数据到达时(到达网卡并拷贝到了内核缓冲区),立刻返回一个错误值(-1),而不是阻塞地等待。
操作系统提供了这样的功能,只需要在调用 read 前,将文件描述符设置为非阻塞即可。
fcntl(connfd, F_SETFL, O_NONBLOCK);
int n = read(connfd, buffer) != SUCCESS);这样,就需要用户线程循环调用 read,直到返回值不为 -1,再开始处理业务。
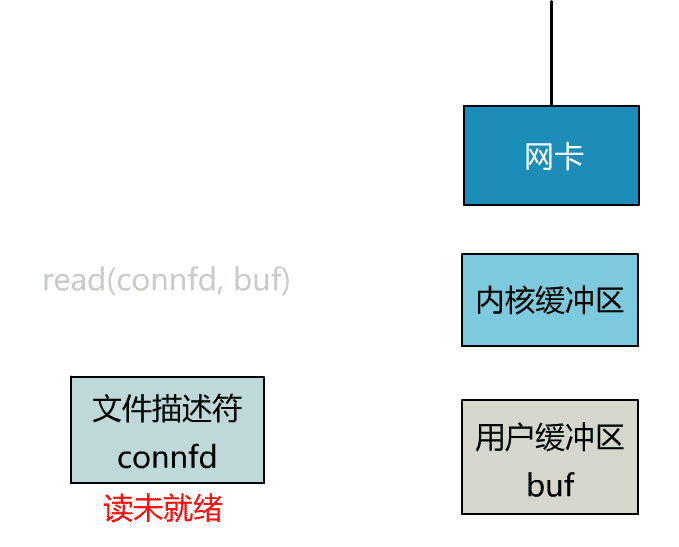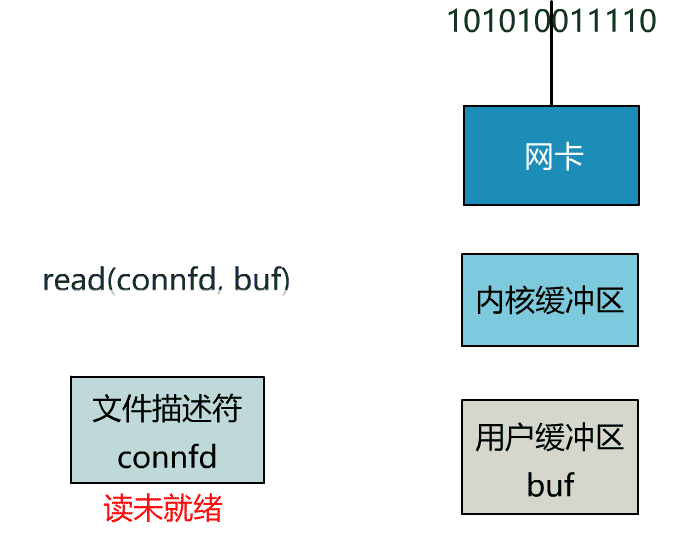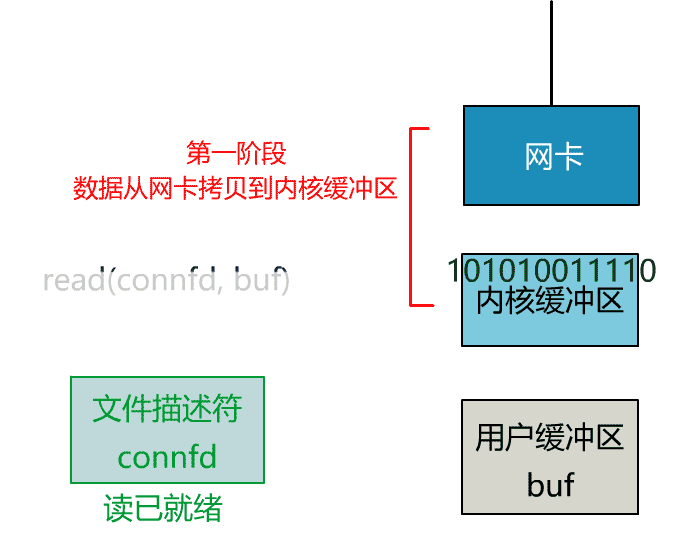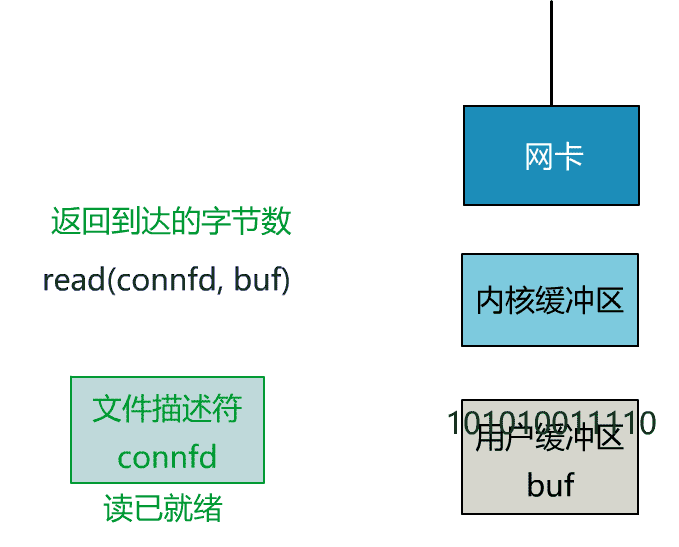
这里我们注意到一个细节。
非阻塞的 read,指的是在数据到达前,即数据还未到达网卡,或者到达网卡但还没有拷贝到内核缓冲区之前,这个阶段是非阻塞的。
当数据已到达内核缓冲区,此时调用 read 函数仍然是阻塞的,需要等待数据从内核缓冲区拷贝到用户缓冲区,才能返回。
整体流程如下图。
IO 多路复用
为每个客户端创建一个线程,服务器端的线程资源很容易被耗光。
当然还有个聪明的办法,我们可以每 accept 一个客户端连接后,将这个文件描述符(connfd)放到一个数组里。
fdlist.add(connfd);然后弄一个新的线程去不断遍历这个数组,调用每一个元素的非阻塞 read 方法。
while(1) {
for(fd <-- fdlist) {
if(read(fd) != -1) {
doSomeThing();
}
}
}这样,我们就成功用一个线程处理了多个客户端连接。
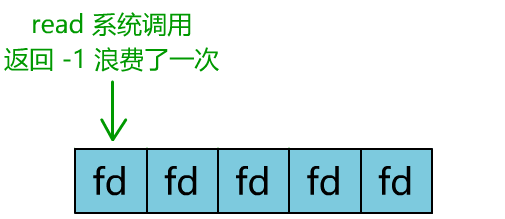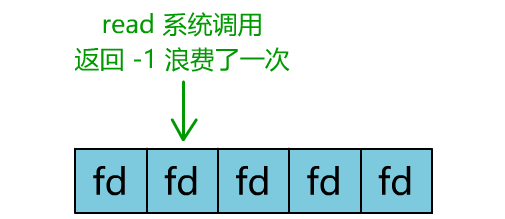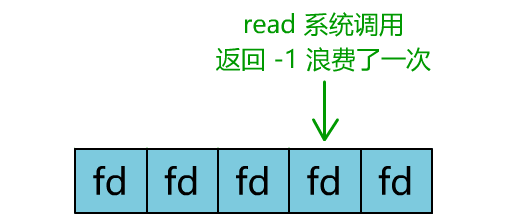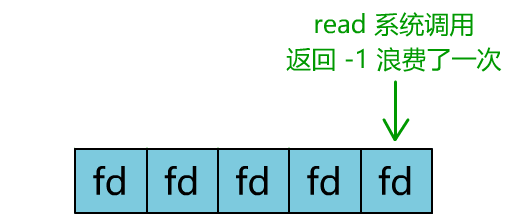
你是不是觉得这有些多路复用的意思?
但这和我们用多线程去将阻塞 IO 改造成看起来是非阻塞 IO 一样,这种遍历方式也只是我们用户自己想出的小把戏,每次遍历遇到 read 返回 -1 时仍然是一次浪费资源的系统调用。
在 while 循环里做系统调用,就好比你做分布式项目时在 while 里做 rpc 请求一样,是不划算的。
所以,还是得恳请操作系统老大,提供给我们一个有这样效果的函数,我们将一批文件描述符通过一次系统调用传给内核,由内核层去遍历,才能真正解决这个问题。
select
select 是操作系统提供的系统调用函数,通过它,我们可以把一个文件描述符的数组发给操作系统, 让操作系统去遍历,确定哪个文件描述符可以读写, 然后告诉我们去处理:
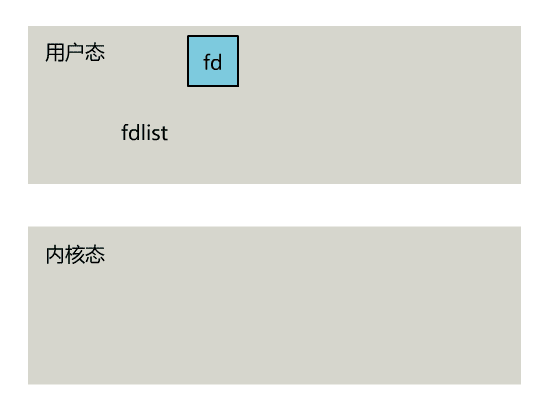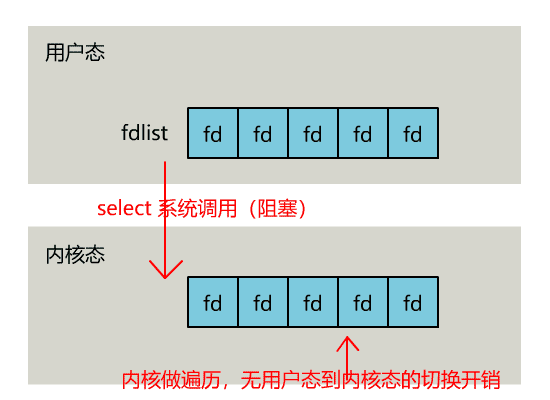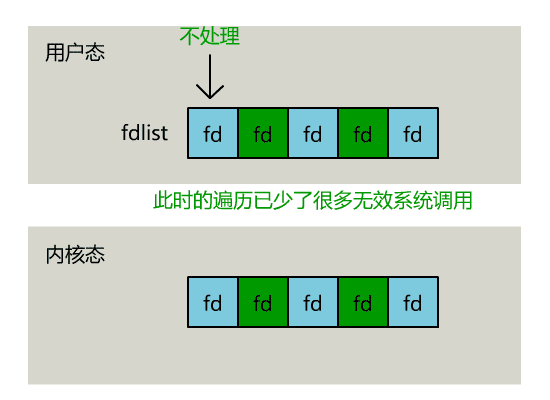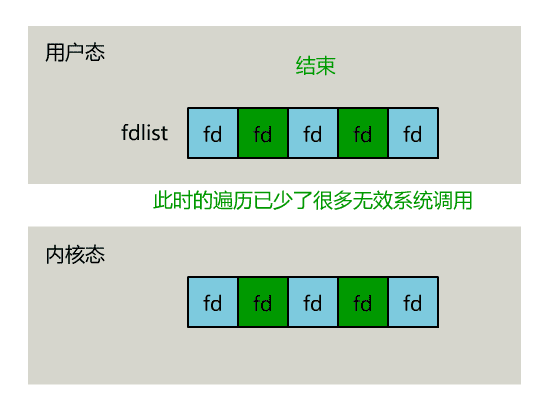
select系统调用的函数定义如下。
int select(
int nfds,
fd_set *readfds,
fd_set *writefds,
fd_set *exceptfds,
struct timeval *timeout);
// nfds:监控的文件描述符集里最大文件描述符加1
// readfds:监控有读数据到达文件描述符集合,传入传出参数
// writefds:监控写数据到达文件描述符集合,传入传出参数
// exceptfds:监控异常发生达文件描述符集合, 传入传出参数
// timeout:定时阻塞监控时间,3种情况
// 1.NULL,永远等下去
// 2.设置timeval,等待固定时间
// 3.设置timeval里时间均为0,检查描述字后立即返回,轮询服务端代码,这样来写。
首先一个线程不断接受客户端连接,并把 socket 文件描述符放到一个 list 里。
while(1) {
connfd = accept(listenfd);
fcntl(connfd, F_SETFL, O_NONBLOCK);
fdlist.add(connfd);
}然后,另一个线程不再自己遍历,而是调用 select,将这批文件描述符 list 交给操作系统去遍历。
while(1) {
// 把一堆文件描述符 list 传给 select 函数
// 有已就绪的文件描述符就返回,nready 表示有多少个就绪的
nready = select(list);
...
}不过,当 select 函数返回后,用户依然需要遍历刚刚提交给操作系统的 list。
只不过,操作系统会将准备就绪的文件描述符做上标识,用户层将不会再有无意义的系统调用开销。
while(1) {
nready = select(list);
// 用户层依然要遍历,只不过少了很多无效的系统调用
for(fd <-- fdlist) {
if(fd != -1) {
// 只读已就绪的文件描述符
read(fd, buf);
// 总共只有 nready 个已就绪描述符,不用过多遍历
if(--nready == 0) break;
}
}
}正如刚刚的动图中所描述的,其直观效果如下。(同一个动图消耗了你两次流量,气不气?)
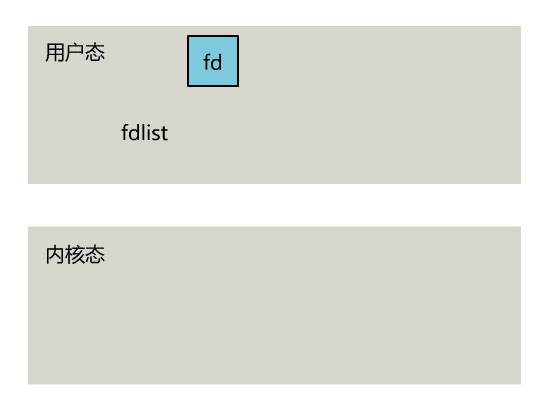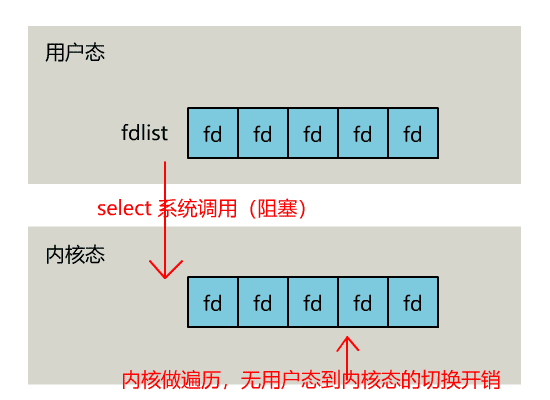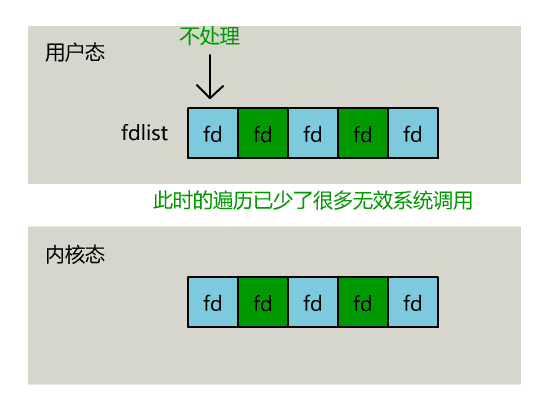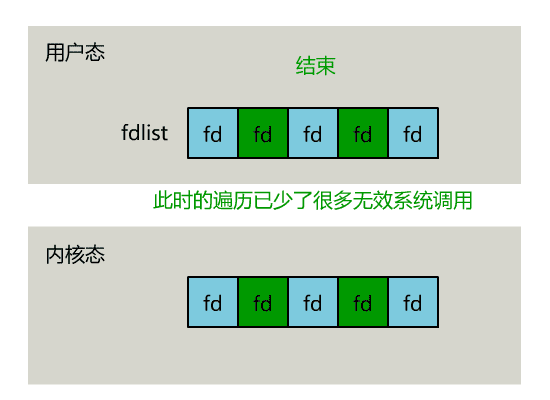
可以看出几个细节:
- null
- select 调用需要传入 fd 数组,需要拷贝一份到内核,高并发场景下这样的拷贝消耗的资源是惊人的。(可优化为不复制)
- select 在内核层仍然是通过遍历的方式检查文件描述符的就绪状态,是个同步过程,只不过无系统调用切换上下文的开销。(内核层可优化为异步事件通知)
- select 仅仅返回可读文件描述符的个数,具体哪个可读还是要用户自己遍历。(可优化为只返回给用户就绪的文件描述符,无需用户做无效的遍历)
整个 select 的流程图如下。
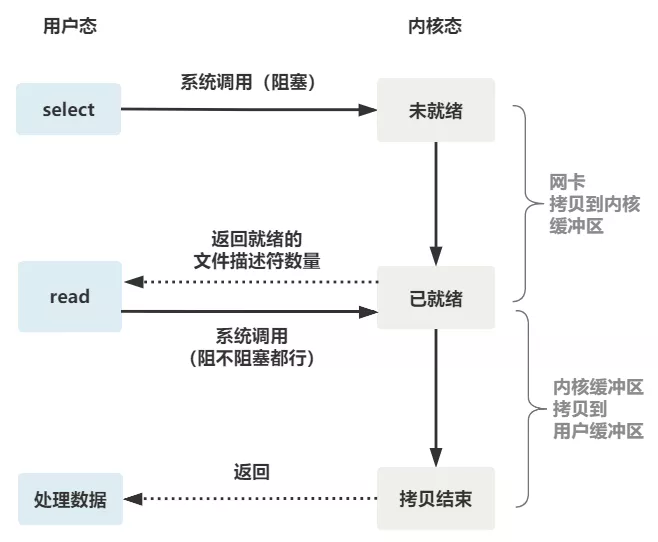
可以看到,这种方式,既做到了一个线程处理多个客户端连接(文件描述符),又减少了系统调用的开销(多个文件描述符只有一次 select 的系统调用 + n 次就绪状态的文件描述符的 read 系统调用)。
poll
poll 也是操作系统提供的系统调用函数。
int poll(struct pollfd *fds, nfds_tnfds, int timeout);
struct pollfd {
intfd; /*文件描述符*/
shortevents; /*监控的事件*/
shortrevents; /*监控事件中满足条件返回的事件*/
};它和 select 的主要区别就是,去掉了 select 只能监听 1024 个文件描述符的限制。
epoll
epoll 是最终的大 boss,它解决了 select 和 poll 的一些问题。
还记得上面说的 select 的三个细节么?
- select 调用需要传入 fd 数组,需要拷贝一份到内核,高并发场景下这样的拷贝消耗的资源是惊人的。(可优化为不复制)
- select 在内核层仍然是通过遍历的方式检查文件描述符的就绪状态,是个同步过程,只不过无系统调用切换上下文的开销。(内核层可优化为异步事件通知)
- select 仅仅返回可读文件描述符的个数,具体哪个可读还是要用户自己遍历。(可优化为只返回给用户就绪的文件描述符,无需用户做无效的遍历)
所以 epoll 主要就是针对这三点进行了改进。
- 内核中保存一份文件描述符集合,无需用户每次都重新传入,只需告诉内核修改的部分即可。
- 内核不再通过轮询的方式找到就绪的文件描述符,而是通过异步 IO 事件唤醒。
- 内核仅会将有 IO 事件的文件描述符返回给用户,用户也无需遍历整个文件描述符集合。
具体,操作系统提供了这三个函数。
第一步,创建一个 epoll 句柄
int epoll_create(int size);第二步,向内核添加、修改或删除要监控的文件描述符。
int epoll_ctl(
int epfd, int op, int fd, struct epoll_event *event);第三步,类似发起了 select() 调用
int epoll_wait(
int epfd, struct epoll_event *events, int max events, int timeout);使用起来,其内部原理就像如下一般丝滑。

总结
大白话总结一下。
一切的开始,都起源于这个 read 函数是操作系统提供的,而且是阻塞的,我们叫它 阻塞 IO。
为了破这个局,程序员在用户态通过多线程来防止主线程卡死。
后来操作系统发现这个需求比较大,于是在操作系统层面提供了非阻塞的 read 函数,这样程序员就可以在一个线程内完成多个文件描述符的读取,这就是 非阻塞 IO。
但多个文件描述符的读取就需要遍历,当高并发场景越来越多时,用户态遍历的文件描述符也越来越多,相当于在 while 循环里进行了越来越多的系统调用。
后来操作系统又发现这个场景需求量较大,于是又在操作系统层面提供了这样的遍历文件描述符的机制,这就是 IO 多路复用。
多路复用有三个函数,最开始是 select,然后又发明了 poll 解决了 select 文件描述符的限制,然后又发明了 epoll 解决 select 的三个不足。
所以,IO 模型的演进,其实就是时代的变化,倒逼着操作系统将更多的功能加到自己的内核而已。
如果你建立了这样的思维,很容易发现网上的一些错误。
比如好多文章说,多路复用之所以效率高,是因为用一个线程就可以监控多个文件描述符。
这显然是知其然而不知其所以然,多路复用产生的效果,完全可以由用户态去遍历文件描述符并调用其非阻塞的 read 函数实现。而多路复用快的原因在于,操作系统提供了这样的系统调用,使得原来的 while 循环里多次系统调用,变成了一次系统调用 + 内核层遍历这些文件描述符。
就好比我们平时写业务代码,把原来 while 循环里调 http 接口进行批量,改成了让对方提供一个批量添加的 http 接口,然后我们一次 rpc 请求就完成了批量添加,一个道理。
参考资料
- https://www.bilibili.com/video/BV1yt4y1D7AS
- https://www.bilibili.com/video/BV1YA411J7kq
- https://mp.weixin.qq.com/s/YdIdoZ_yusVWza1PU7lWaw

最后,欢迎关注我的个人微信公众号:业余草(yyucao)!可加作者微信号:xttblog2。备注:“1”,添加博主微信拉你进微信群。备注错误不会同意好友申请。再次感谢您的关注!后续有精彩内容会第一时间发给您!原创文章投稿请发送至532009913@qq.com邮箱。商务合作也可添加作者微信进行联系!
本文原文出处:业余草: » 图文并茂的给你讲清IO多路复用、select模型、poll模型、epoll模型