
本博客日IP超过2000,PV 3000 左右,急需赞助商。
极客时间所有课程通过我的二维码购买后返现24元微信红包,请加博主新的微信号:xttblog2,之前的微信号好友位已满,备注:返现
受密码保护的文章请关注“业余草”公众号,回复关键字“0”获得密码
所有面试题(java、前端、数据库、springboot等)一网打尽,请关注文末小程序

【腾讯云】1核2G5M轻量应用服务器50元首年,高性价比,助您轻松上云
不管你是用百度还是谷歌,都有一套权重算法。以百度为例,权重越高,搜索出来的结果排名就越靠前。同理 Lucene 的对搜索结果是如何排序的呢?答案是对搜索词的权重(Term weight)计算。本文将介绍一下 Lucene 的权重(PR)计算方式。
找出词(Term) 对文档的重要性的过程称为计算词的权重(Term weight) 的过程。
计算词的权重(term weight)有两个参数,第一个是词(Term),第二个是文档(Document)。
词的权重(Term weight)表示此词(Term)在此文档中的重要程度,越重要的词(Term)有越大的权重(Term weight),因而在计算文档之间的相关性中将发挥更大的作用。

判断词(Term) 之间的关系从而得到文档相关性的过程应用一种叫做向量空间模型的算法(Vector Space Model) 。
下面仔细分析一下这两个过程:
计算权重(Term weight)的过程
影响一个词(Term)在一篇文档中的重要性主要有两个因素:
- Term Frequency (tf):即此Term在此文档中出现了多少次。tf 越大说明越重要。
- Document Frequency (df):即有多少文档包含次Term。df 越大说明越不重要。
容易理解吗?词(Term)在文档中出现的次数越多,说明此词(Term)对该文档越重要,如“搜索”这个词,在本文档中出现的次数很多,说明本文档主要就是讲这方面的事的。然而在一篇英语文档中,this出现的次数更多,就说明越重要吗?不是的,这是由第二个因素进行调整,第二个因素说明,有越多的文档包含此词(Term), 说明此词(Term)太普通,不足以区分这些文档,因而重要性越低。
这也如我们程序员所学的技术,对于程序员本身来说,这项技术掌握越深越好(掌握越深说明花时间看的越多,tf越大),找工作时越有竞争力。然而对于所有程序员来说,这项技术懂得的人越少越好(懂得的人少df小),找工作越有竞争力。人的价值在于不可替代性就是这个道理。
道理明白了,我们来看看公式:

这仅仅只term weight计算公式的简单典型实现。实现全文检索系统的人会有自己的实现,Lucene就与此稍有不同。
向量空间模型的算法(VSM)
判断Term之间的关系从而得到文档相关性的过程,也即向量空间模型的算法(VSM)。
我们把文档看作一系列词(Term),每一个词(Term)都有一个权重(Term weight),不同的词(Term)根据自己在文档中的权重来影响文档相关性的打分计算。
于是我们把所有此文档中词(term)的权重(term weight) 看作一个向量。
Document = {term1, term2, …… ,term N}
Document Vector = {weight1, weight2, …… ,weight N}
同样我们把查询语句看作一个简单的文档,也用向量来表示。
Query = {term1, term 2, …… , term N}
Query Vector = {weight1, weight2, …… , weight N}
我们把所有搜索出的文档向量及查询向量放到一个N维空间中,每个词(term)是一维。
如图:
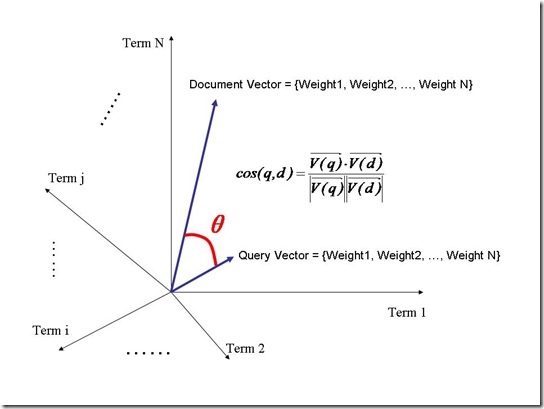
我们认为两个向量之间的夹角越小,相关性越大。
所以我们计算夹角的余弦值作为相关性的打分,夹角越小,余弦值越大,打分越高,相关性越大。
有人可能会问,查询语句一般是很短的,包含的词(Term)是很少的,因而查询向量的维数很小,而文档很长,包含词(Term)很多,文档向量维数很大。你的图中两者维数怎么都是N呢?
在这里,既然要放到相同的向量空间,自然维数是相同的,不同时,取二者的并集,如果不含某个词(Term)时,则权重(Term Weight)为0。
相关性打分公式如下:
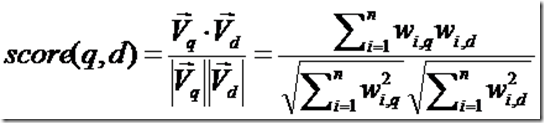
举个例子,查询语句有11个Term,共有三篇文档搜索出来。其中各自的权重(Term weight),如下表格。
|
|
t1 |
t2 |
t3 |
t4 |
t5 |
t6 |
t7 |
t8 |
t9 |
t10 |
t11 |
|
D1 |
0 |
0 |
.477 |
0 |
.477 |
.176 |
0 |
0 |
0 |
.176 |
0 |
|
D2 |
0 |
.176 |
0 |
.477 |
0 |
0 |
0 |
0 |
.954 |
0 |
.176 |
|
D3 |
0 |
.176 |
0 |
0 |
0 |
.176 |
0 |
0 |
0 |
.176 |
.176 |
|
Q |
0 |
0 |
0 |
0 |
0 |
.176 |
0 |
0 |
.477 |
0 |
.176 |
于是计算,三篇文档同查询语句的相关性打分分别为:
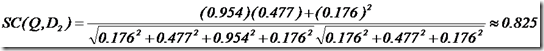
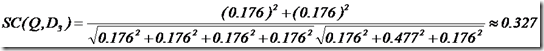
于是文档二相关性最高,先返回,其次是文档一,最后是文档三。
到此为止,我们可以找到我们最想要的文档了。
说了这么多,其实还没有进入到Lucene,而仅仅是信息检索技术(Information retrieval)中的基本理论,然而当我们看过Lucene后我们会发现,Lucene是对这种基本理论的一种基本的的实践。所以在以后分析Lucene的文章中,会常常看到以上理论在Lucene中的应用。
在进入Lucene之前,对上述索引创建和搜索过程所一个总结,如图:
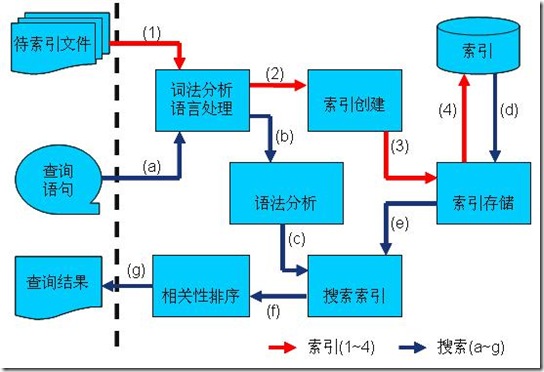
索引过程
- 有一系列被索引文件
- 被索引文件经过语法分析和语言处理形成一系列词(Term) 。
- 经过索引创建形成词典和反向索引表。
- 通过索引存储将索引写入硬盘。
搜索过程
- 用户输入查询语句。
- 对查询语句经过语法分析和语言分析得到一系列词(Term) 。
- 通过语法分析得到一个查询树。
- 通过索引存储将索引读入到内存。
- 利用查询树搜索索引,从而得到每个词(Term) 的文档链表,对文档链表进行交,差,并得到结果文档。
- 将搜索到的结果文档对查询的相关性进行排序。
- 返回查询结果给用户。
参考资料

最后,欢迎关注我的个人微信公众号:业余草(yyucao)!可加作者微信号:xttblog2。备注:“1”,添加博主微信拉你进微信群。备注错误不会同意好友申请。再次感谢您的关注!后续有精彩内容会第一时间发给您!原创文章投稿请发送至532009913@qq.com邮箱。商务合作也可添加作者微信进行联系!
本文原文出处:业余草: » 详解 Lucene 对 Term的权重(Term weight) 计算