
本博客日IP超过2000,PV 3000 左右,急需赞助商。
极客时间所有课程通过我的二维码购买后返现24元微信红包,请加博主新的微信号:xttblog2,之前的微信号好友位已满,备注:返现
受密码保护的文章请关注“业余草”公众号,回复关键字“0”获得密码
所有面试题(java、前端、数据库、springboot等)一网打尽,请关注文末小程序

【腾讯云】1核2G5M轻量应用服务器50元首年,高性价比,助您轻松上云
前文阐述了通过 脑裂,两地三中心方案, 为了解决分布式系统中的节点故障的问题,系统引入了两个组件 Agent、Center,作为调度模块。而如果在运行过程中,Agent、Center 本身也会出现主机宕机、网络故障等异常场景呢?我们梳理了分布式的调度系统中常见的故障:
- 故障一:Center 宕机:在执行容灾过程当中,Center 主机发生宕机,导致容灾流程中途失败?
- 故障二:状态误判:Tbase 系统本身运行正常,但由于 Center 和 Agent 之间的网络故障,Center 对 Agent 所监控的 DN 状态发生误判,导致 Center 在 Tbase 系统正常运行的情况下,发出错误的容灾倒换指令?
- 故障三:指令超时:Center 向 Agent 发送的指令都是通过网络包进行发送,会出现指令丢失或者指令超时?
- 故障四:指令乱序:Agent 在执行指令的过程中,会向 Center 反馈自身的执行状态,由于各种原因,当 Agent 回复的指令出现了乱序怎么办?
针对上述故障场景,Tbase 容灾系统提出了如下解决方案:
- 任务接管:引入主备 Center,用于解决 Center 在容灾流程中发生宕机或者网络故障等问题。
- 状态仲裁:引入 ZK 集群,保证所有节点状态的一致性,避免 Center 状态误判,发起误容灾。
- 超时重试:通过超时重试机制,解决 Agent、Center 网络通信过程中,出现的网络超时的问题。
- 指令 ID:对每条指令分配全局唯一 ID 号进行编码,解决 Agent、Center 网络通信过程中,出现指令乱序的问题。
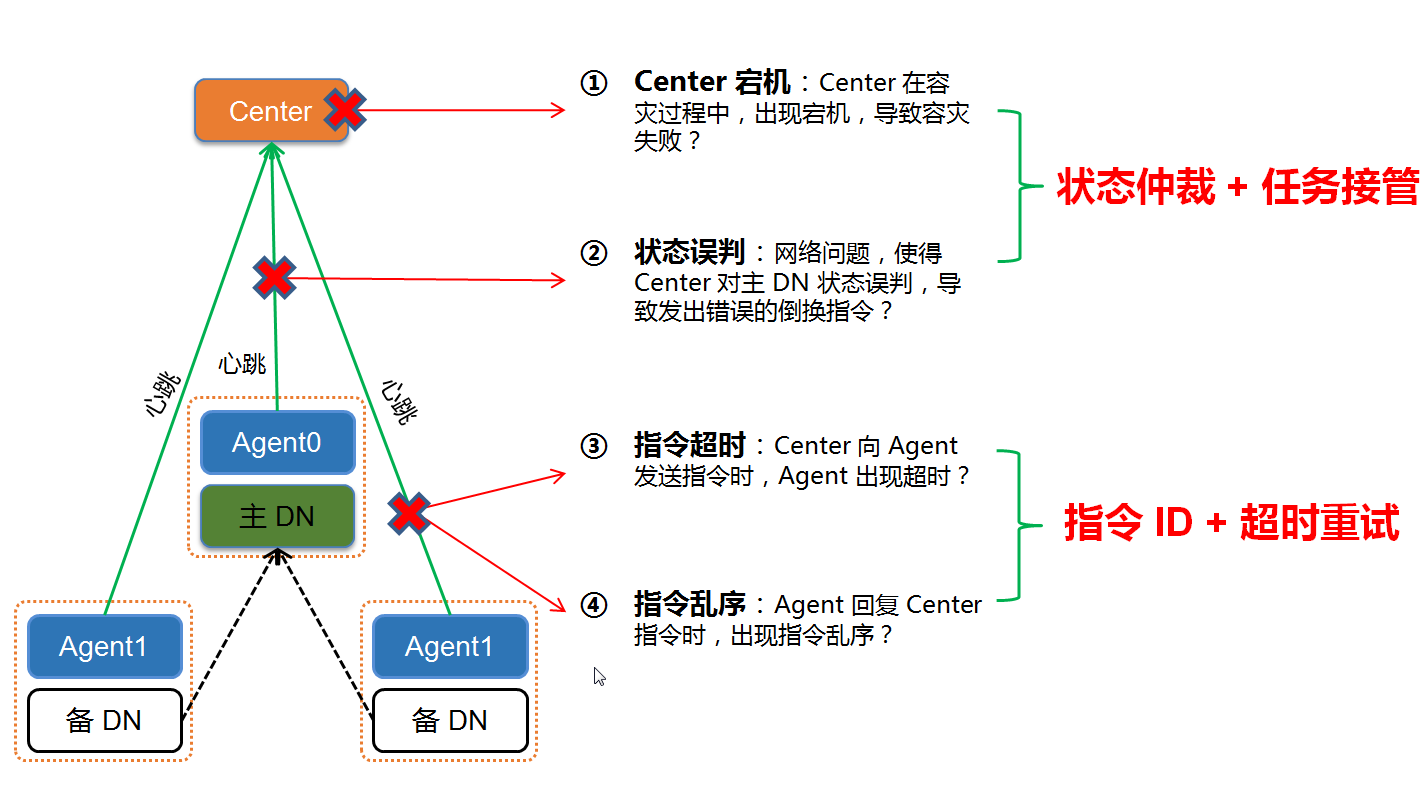
通过 状态仲裁 和 任务接管 解决Center误容灾和 Center 容灾过程中发生宕机的问题,如下图图所示,分布式系统可以做如下操作:
- 节点异常:当 DN 节点异常后,Agent 采集节点状态信息,将异常状态上报给所有 Center。
- 状态仲裁:当 Master Center 收到节点状态异常后,不会立即发起容灾流程,而是向所有 Slave Center 发起状态仲裁请求。
- 状态获取:Slave Center 收到状态请求后,向 ZK 拉取节点状态,并回复给 Master Center。
- 启动容灾:当超过多半 Slave Center 认定该节点异常后,Master Center 发起容灾流程。
- 执行容灾:Master Center 生成容灾指令计划,并向各个 Agent 发起容灾指令,并监听 Agent 的指令执行状态,同时将容灾日志持久化到配置库。
- Center 宕机:在容灾过程中,如果 Master Center 发生宕机,ZK 会发起选主流程,从 Slave Center 中选择一个新的 Master Center。
- 任务接管:新的 Master Center 选定后,会从配置库中拉取容灾日志,重新生成容灾指令计划,继续向 Agent 发送容灾指令,完成剩余容灾流程。
- Center 重启:原 Master Center 宕机重启后,从 ZK 获取自身角色,发现已经被降级成 Slave,不再恢复容灾流程,自动转换成新的 Slave Center 运行,保证系统不会出现 Center 脑裂。
通过 状态仲裁 保证DN 状态的一致性,避免因Center对DN状态的误判,发起误容灾;通过 任务接管 确保在 Center 宕机 等故障场景下,容灾仍然能够继续执行;通过 ZK 选主,保证系统在任何时刻都只能够存在唯一的一个 Master Center,避免出现 Center 脑裂。
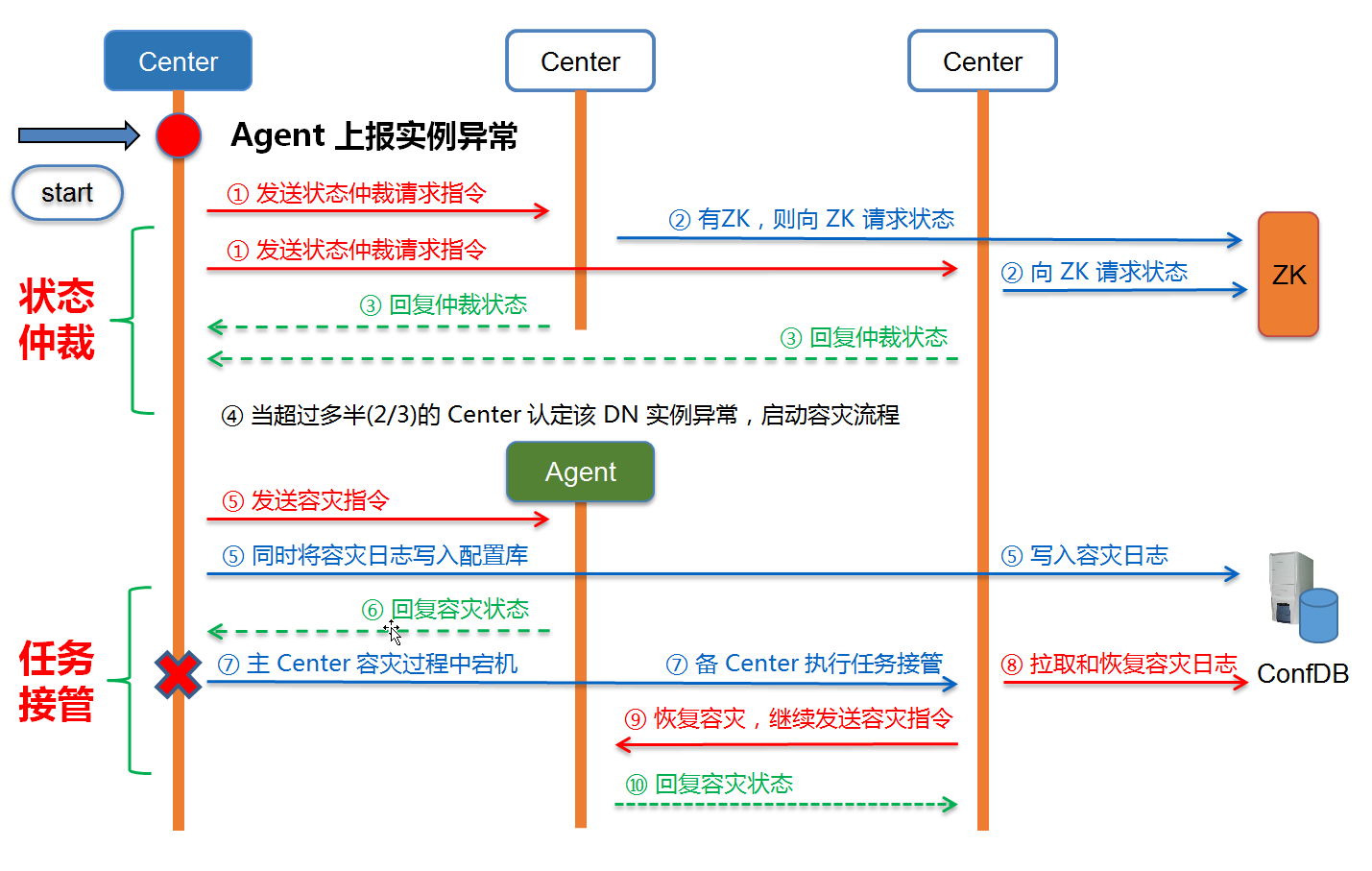
引入 超时重试 和 指令 ID 解决 Agent、Center 网络消息超时和消息乱序的问题,如上图所示,具体流程如下:
- 超时重试:Center 发送指令给 Agent 后,会监听指令的执行状态,超过一定时间没有收到 Agent 的回复,执行指令重试。
- 指令 ID:Center 在下发每一条指令的时候,会对指令进行编码,赋予一个全局递增的唯一 ID 号,一起下发给 Agent,Agent 在回复 Center 执行状态时,必须将原来的指令 ID 一起回复给 Center。
- ID 递增:当 Center 收到 Agent 回复后,根据需要选择继续监听,还是下发下一个指令,如果下发下一个指令,Center 首先将指令 ID 递增,然后再下发指令。
- 消息过滤:递增 ID,一方面表示 ,Center 更新了本身的任务状态,另一方面表示,针对 Agent 回复的消息,如果 ID 小于Center 当前的 ID 号,则 Center 不予处理,直接过滤即可。
通过 超时重试 确保在网络抖动等异常情况下,Center 仍然能够正常发送指令计划;通过 指令 ID 确保 Center 能够时时更新自身的任务状态,忽略 Agent 反馈的过期消息,防止由于网络问题导致 Agent 回复的消息出现指令乱序。

最后,欢迎关注我的个人微信公众号:业余草(yyucao)!可加作者微信号:xttblog2。备注:“1”,添加博主微信拉你进微信群。备注错误不会同意好友申请。再次感谢您的关注!后续有精彩内容会第一时间发给您!原创文章投稿请发送至532009913@qq.com邮箱。商务合作也可添加作者微信进行联系!
本文原文出处:业余草: » Tbase分布式系统容灾中的调度节点容灾问题