
本博客日IP超过2000,PV 3000 左右,急需赞助商。
极客时间所有课程通过我的二维码购买后返现24元微信红包,请加博主新的微信号:xttblog2,之前的微信号好友位已满,备注:返现
受密码保护的文章请关注“业余草”公众号,回复关键字“0”获得密码
所有面试题(java、前端、数据库、springboot等)一网打尽,请关注文末小程序

【腾讯云】1核2G5M轻量应用服务器50元首年,高性价比,助您轻松上云
最近在学习和使用 Lucene,所以我想对 Lucene 的内部实现,它的一些组件等有一系列详细的理解。在上一篇的基础上《详解 org.apache.lucene.analysis.Analyzer 使用教程》我们来说说 Analyzer 的内部构成吧,TokenStream、Tokenizer、TokenFilter。
Analyzer 分词器,实际上就是一个文本的分析过程,或者说是将输入文本转化为文本特征向量的过程。具体的文本特征,可以是词或者是短语。Analyzer 的执行流程可以概括为以下四个步骤:
- 分词,将文本解析为单词或短语
- 归一化,将文本转化为小写
- 停用词处理,去除一些常用的、无意义的词
- 提取词干,解决单复数、时态语态等问题
Lucene 的 Analyzer 包含两个核心组件,Tokenizer 以及 TokenFilter。它们两个组成了 TokenStream。Tokenizer 和 TokenFilter 两者的区别在于,前者在字符级别处理流,而后者则在词语级别处理流。
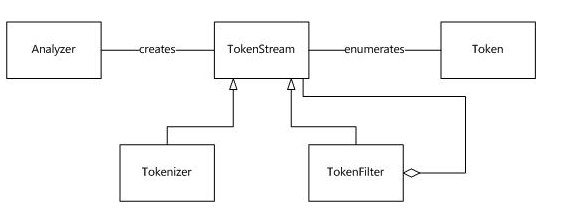
Tokenizer 是 Analyzer 的第一步,其构造函数接收一个 Reader 作为参数,或者是字符串参数,而 TokenFilter 则是一个类似拦截器的东东,其参数可以使 TokenStream、Tokenizer,甚至是另一个 TokenFilter。
上图已经详细的介绍了 Analyzer 的内部构造。上图中的一些名词的解释如下表所示:
| 类 | 说明 |
| Token | 表示文中出现的一个词,它包含了词在文本中的位置信息 |
| Analyzer | 将文本转化为TokenStream的工具 |
| TokenStream | 文本符号的流 |
| Tokenizer | 在字符级别处理输入符号流 |
| TokenFilter | 在字符级别处理输入符号流,其输入可以是TokenStream、Tokenizer或者TokenFilter |
在 Lucene Analyzer 中,Tokenizer 和 TokenFilter 的组织架构如下图所示:
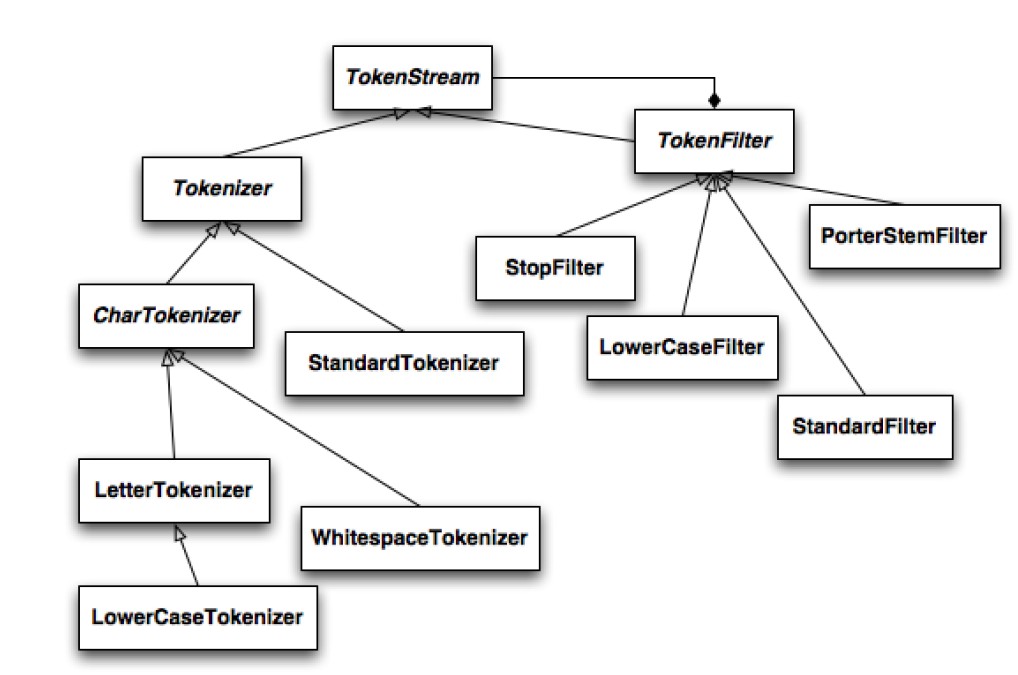
Lucene 提供了数十种内置的 Tokenizer、TokenFilter 以及 Analyzer 供开发人员使用,事实上大部分时候我们只会需要使用其中的某几种,比如标准分词器 StandardTokenizer、空格分词器 WhitespaceTokenizer、转化为小写格式的 LowCaseFilter、提取词干的 PoterStemFilter 以及组合使用 StandardTokenizer 和多种 TokenFilter 的 StandardAnalyzer 等。
Analyzer、TokenStream(Token、Tokenizer、Tokenfilter)之间的关系解释如下:
TokenStream 是用来走访 Token 的 iterator(迭代器),Tokenizer 继承自 TokenStream,其输入为 Reader 。TokenFilter 继承自 TokenStream,其作用是用来完成对 TokenStream 的过滤操作,譬如去 StopWords,将 Token 变为小写等。
TokenStream 分词流,即将对象分词后所得的 Token 在内存中以流的方式存在,也说是说如果在取得 Token 必须从 TokenStream 中获取,而分词对象可以是文档文本,也可以是查询文本。
Token:如果一个字段被 token 化,这表示它经过了一个可将内容转化为 tokens 串的分析程序。 Token 是建立索引的基本单位,表示每个被编入索引的字符。 在 token 化的过程中,分析程序会在使用任何转换逻辑(例如去掉 "a” 或 "the" 这类停用词,执行词干搜寻,将无大小写区分的所有文字转换成小写等)的同时,抽取应被编入索引的文本内容。由于和字段相关的内容减少到只剩核心元素,因此,索引作为与某个字段相关的文字内容,它的规模也被缩小了。只有被 token 化的字段也将被编入索引的情况下才有意义。
Analyzer 就是一个 TokenStream 工厂。主要的分词环节是 Tokenizer 类执行,而 Filter 负责数据的预处理和分词后处理且数量不限。
TokenStream
TokenStream 是一个抽象类,枚举词序列,要么是从一个文档的域得来,要么是从一个查询文本中得到。主要任务有:
- 获取下一Token;public Token next();取得词序列中的下一个词,public Token next(final Token reusableToken);输入可复用的 Token,作为初始参数,可以返回一个新的 Token。在Lucene3以后,next方法改为了incrementToken,并增加了end方法。
- 重设流(可选); public void reset();
- 关闭流,释放资源; public void close();
Tokenizer
Tokenizer 类是继承于 TokenStream 的一个抽象类,是一个输入为 Reader 的 TokenStream。其职责是:接收输入流并根据输入流进行词切分。因此,该类是定制分词器的核心之一。在 Tokenizer 类中,核心的方法是 next 方法。
TokenFilter
TokenFilter 类继承于 TokenStream,其输入是另一个 TokenStream,主要职责是对 TokenStream 进行过滤,例如去掉一些索引词、替代同义索引词等操作。
Token 属性
lucene 里定义了几种基本属性:
- TermAttribute:表示token的字符串信息。比如"I'm";
- TypeAttribute:表示token词典类别信息,默认为“Word”,比如I'm就属于<APOSTROPHE>,有撇号的类型;
- OffsetAttribute:表示token的首字母和尾字母在原文本中的位置。比如I'm的位置信息就是(0,3),需要注意的是startOffset与endOffset的差值并不一定就是termText.length(),因为可能term已经用stemmer或者其他过滤器处理过;
- PositionIncrementAttribute:这个有点特殊,它表示tokenStream中的当前token与前一个token在实际的原文本中相隔的词语数量,用于短语查询。比如: 在tokenStream中[2:a]的前一个token是[1:I’m ],它们在原文本中相隔的词语数是1,则token="a"的PositionIncrementAttribute值为1;
- PayloadAttribute,payload即负载量意思,是每个term出现一次则存储一次的元数据,它存储于特定term的posting list内部。
- FlagsAttribute,用于在Tokenizer链之前传递标记(因为前面一个操作可能会影响后面的操作)。
本文就先到这里,更多关于 Lucene 的知识,我们后面继续。

最后,欢迎关注我的个人微信公众号:业余草(yyucao)!可加作者微信号:xttblog2。备注:“1”,添加博主微信拉你进微信群。备注错误不会同意好友申请。再次感谢您的关注!后续有精彩内容会第一时间发给您!原创文章投稿请发送至532009913@qq.com邮箱。商务合作也可添加作者微信进行联系!
本文原文出处:业余草: » 深入理解 Lucene 的 Analyzer