
本博客日IP超过2000,PV 3000 左右,急需赞助商。
极客时间所有课程通过我的二维码购买后返现24元微信红包,请加博主新的微信号:xttblog2,之前的微信号好友位已满,备注:返现
受密码保护的文章请关注“业余草”公众号,回复关键字“0”获得密码
所有面试题(java、前端、数据库、springboot等)一网打尽,请关注文末小程序

【腾讯云】1核2G5M轻量应用服务器50元首年,高性价比,助您轻松上云
所有建立索引的目的就是为了检索。 索引一般只需要建立一次,但是搜索才是核心。建立索引的目的就是为了检索。IndexSearcher 索引搜索器是 Lucene 中核心的核心,是搜索过程中最重要的和核心组件。本文介绍一些关于 IndexSearcher 的相关知识。
org.apache.lucene.search.IndexSearcher 类有几个重要的构造函数。
- IndexSearcher(IndexReader r):创建一个搜索 searching 提供索引
- IndexSearcher(IndexReader r, ExecutorService executor):运行搜索单独各段,使用提供的 ExecutorService
- IndexSearcher(IndexReaderContext context, ExecutorService executor):同上一个类似
- IndexSearcher(IndexReaderContext context):同上一个类似
Lucene 中针对搜索提供了非常多的 API,但是它们总的来说,可以将它们归纳为 5 类:
| 类 | 目的 |
|---|---|
| IndexSearcher | 搜索索引的核心类。所有搜索都通过IndexSearcher进行,它们会调用该类中重载的search方法 |
| Query及其子类 | 封装某种查询类型的具体子类。Query实例将被传递给IndexSearcher的search方法 |
| QueryParser | 将用户输入的可读的查询表达式处理成具体的Query对象 |
| TopDocs | 保持由IndexSearcher.search()方法返回的具有较高评分的顶部文档 |
| ScoreDoc | 提供对TopDocs中每条搜索结果的访问接口 |
IndexSearcher 里面有非常多的内部类,看的眼花缭乱,但是归纳一下,大体可以总结出 6 点重要内容:
- 提供了对单个 IndexReader 的查询实现
- 通常应用程序只需要调用 search(Query, int) 或者 search(Query, Filter, int) 方法
- 如果你的索引不变,在多个搜索中应该采用共享一个 IndexSearcher 实例的方式
- 如果索引有变动,并且你希望在搜索中有所体现,那么应该使用 DirectoryReader.openIfChanged(DirectoryReader) 来获取新的 reader,然后通过这个 reader 创建一个新的 IndexSearcher
- 为了低延迟查询,最好使用近实时搜索(NRT),此时构建 IndexSearcher 需要使用 DirectoryReader.open(IndexWriter),一旦你获取一个新的 IndexReader,再去创建一个 IndexSearcher 所付出的代价要小的多
- IndexSearcher 实例是完全线程安全的,这意味着多个线程可以并发调用任何方法。如果需要外部同步,无需对 IndexSearcher 实例进行同步
Lucene 的多样化查询都是靠各个 Query 类来实现的。常用的 Query 类有以下 11 个。
- 通过项进行搜索 TermQuery 类
- 在指定的项范围内搜索 TermRangeQuery 类
- 通过字符串搜索 PrefixQuery 类
- 组合查询 BooleanQuery 类
- 通过短语搜索 PhraseQuery 类
- 通配符查询 WildcardQuery 类
- 搜索类似项 FuzzyQuery 类
- 匹配所有文档 MatchAllDocsQuery 类
- 不匹配文档 MatchNoDocsQuery 类
- 解析查询表达式 QueryParser 类
- 多短语查询 MultiPhraseQuery 类
Lucene 搜索的基本流程
在 Lucene 中,再复杂的搜索都有规律可循。Lucene 的搜索检索流程如下:
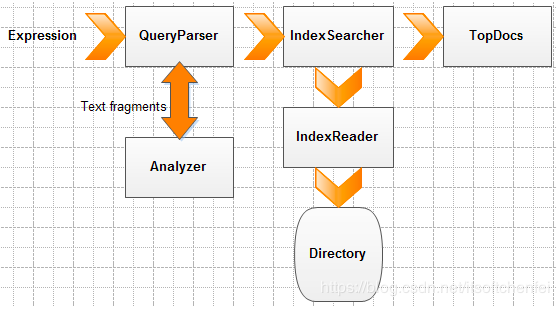
关于各种 Query 类的使用,我们通过下面的实例代码加深大家的认识。
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.core.WhitespaceAnalyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.*;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.RAMDirectory;
import org.apache.lucene.util.BytesRef;
import org.junit.Assert;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.io.StringReader;
public class IndexSearchDemo {
private Directory directory = new RAMDirectory();
private String[] ids = {"1", "2"};
private String[] countries = {"Netherlands", "Italy"};
private String[] contents = {"Amsterdam has lots of bridges", "Venice has lots of canals, not bridges"};
private String[] cities = {"Amsterdam", "Venice"};
private IndexWriterConfig indexWriterConfig = new IndexWriterConfig(new WhitespaceAnalyzer());
private IndexWriter indexWriter;
@Before
public void createIndex() {
try {
indexWriter = new IndexWriter(directory, indexWriterConfig);
for (int i = 0; i < 2; i++) {
Document document = new Document();
Field idField = new StringField("id", ids[i], Field.Store.YES);
Field countryField = new StringField("country", countries[i], Field.Store.YES);
Field contentField = new TextField("content", contents[i], Field.Store.NO);
Field cityField = new StringField("city", cities[i], Field.Store.YES);
document.add(idField);
document.add(countryField);
document.add(contentField);
document.add(cityField);
indexWriter.addDocument(document);
}
indexWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void testTermQuery() throws IOException {
Term term = new Term("id", "2");
IndexSearcher indexSearcher = getIndexSearcher();
TopDocs search = indexSearcher.search(new TermQuery(term), 10);
Assert.assertEquals(1, search.totalHits);
}
@Test
public void testMatchNoDocsQuery() throws IOException {
Query query = new MatchNoDocsQuery();
IndexSearcher indexSearcher = getIndexSearcher();
TopDocs search = indexSearcher.search(query, 10);
Assert.assertEquals(0, search.totalHits);
}
@Test
public void testTermRangeQuery() throws IOException {
//搜索起始字母范围从A到Z的city
Query query = new TermRangeQuery("city", new BytesRef("A"), new BytesRef("Z"), true, true);
IndexSearcher indexSearcher = getIndexSearcher();
TopDocs search = indexSearcher.search(query, 10);
Assert.assertEquals(2, search.totalHits);
}
@Test
public void testQueryParser() throws ParseException, IOException {
//使用WhitespaceAnalyzer分析器不会忽略大小写,也就是说大小写敏感
QueryParser queryParser = new QueryParser("content", new WhitespaceAnalyzer());
Query query = queryParser.parse("+lots +has");
IndexSearcher indexSearcher = getIndexSearcher();
TopDocs search = indexSearcher.search(query, 1);
Assert.assertEquals(2, search.totalHits);
query = queryParser.parse("lots OR bridges");
search = indexSearcher.search(query, 10);
Assert.assertEquals(2, search.totalHits);
//有点需要注意,在QueryParser解析通配符表达式的时候,一定要用引号包起来,然后作为字符串传递给parse函数
query = new QueryParser("field", new StandardAnalyzer()).parse("\"This is some phrase*\"");
Assert.assertEquals("analyzed", "\"? ? some phrase\"", query.toString("field"));
//语法参考:http://lucene.apache.org/core/6_0_0/queryparser/org/apache/lucene/queryparser/classic/package-summary.html#package_description
//使用QueryParser解析"~",~代表编辑距离,~后面参数的取值在0-2之间,默认值是2,不要使用浮点数
QueryParser parser = new QueryParser("city", new WhitespaceAnalyzer());
//例如,roam~,该查询会匹配foam和roams,如果~后不跟参数,则默认值是2
//QueryParser在解析的时候不区分大小写(会全部转成小写字母),所以虽少了一个字母,但是首字母被解析为小写的v,依然不匹配,所以编辑距离是2
query = parser.parse("Venic~2");
search = indexSearcher.search(query, 10);
Assert.assertEquals(1, search.totalHits);
}
@Test
public void testBooleanQuery() throws IOException {
Query termQuery = new TermQuery(new Term("country", "Beijing"));
Query termQuery1 = new TermQuery(new Term("city", "Venice"));
//测试OR查询,或者出现Beijing或者出现Venice
BooleanQuery build = new BooleanQuery.Builder().add(termQuery, BooleanClause.Occur.SHOULD).add(termQuery1, BooleanClause.Occur.SHOULD).build();
IndexSearcher indexSearcher = getIndexSearcher();
TopDocs search = indexSearcher.search(build, 10);
Assert.assertEquals(1, search.totalHits);
//使用BooleanQuery实现 国家是(Italy OR Netherlands) AND contents中包含(Amsterdam)操作
BooleanQuery build1 = new BooleanQuery.Builder().add(new TermQuery(new Term("country", "Italy")), BooleanClause.Occur.SHOULD).add(new TermQuery
(new Term("country",
"Netherlands")), BooleanClause.Occur.SHOULD).build();
BooleanQuery build2 = new BooleanQuery.Builder().add(build1, BooleanClause.Occur.MUST).add(new TermQuery(new Term("content", "Amsterdam")), BooleanClause.Occur
.MUST).build();
search = indexSearcher.search(build2, 10);
Assert.assertEquals(1, search.totalHits);
}
@Test
public void testPhraseQuery() throws IOException {
//设置两个短语之间的跨度为2,也就是说has和bridges之间的短语小于等于均可检索到
PhraseQuery build = new PhraseQuery.Builder().setSlop(2).add(new Term("content", "has")).add(new Term("content", "bridges")).build();
IndexSearcher indexSearcher = getIndexSearcher();
TopDocs search = indexSearcher.search(build, 10);
Assert.assertEquals(1, search.totalHits);
build = new PhraseQuery.Builder().setSlop(1).add(new Term("content", "Venice")).add(new Term("content", "lots")).add(new Term("content",
"canals")).build();
search = indexSearcher.search(build, 10);
Assert.assertNotEquals(1, search.totalHits);
}
@Test
public void testMatchAllDocsQuery() throws IOException {
Query query = new MatchAllDocsQuery();
IndexSearcher indexSearcher = getIndexSearcher();
TopDocs search = indexSearcher.search(query, 10);
Assert.assertEquals(2, search.totalHits);
}
@Test
public void testFuzzyQuery() throws IOException, ParseException {
//注意是区分大小写的,同时默认的编辑距离的值是2
//注意两个Term之间的编辑距离必须小于两者中最小者的长度:the edit distance between the terms must be less than the minimum length term
Query query = new FuzzyQuery(new Term("city", "Veni"));
IndexSearcher indexSearcher = getIndexSearcher();
TopDocs search = indexSearcher.search(query, 10);
Assert.assertEquals(1, search.totalHits);
}
@Test
public void testWildcardQuery() throws IOException {
//*代表0个或者多个字母
Query query = new WildcardQuery(new Term("content", "*dam"));
IndexSearcher indexSearcher = getIndexSearcher();
TopDocs search = indexSearcher.search(query, 10);
Assert.assertEquals(1, search.totalHits);
//?代表0个或者1个字母
query = new WildcardQuery(new Term("content", "?ridges"));
search = indexSearcher.search(query, 10);
Assert.assertEquals(2, search.totalHits);
query = new WildcardQuery(new Term("content", "b*s"));
search = indexSearcher.search(query, 10);
Assert.assertEquals(2, search.totalHits);
}
@Test
public void testPrefixQuery() throws IOException {
//使用前缀搜索以It打头的国家名,显然只有Italy符合
PrefixQuery query = new PrefixQuery(new Term("country", "It"));
IndexSearcher indexSearcher = getIndexSearcher();
TopDocs search = indexSearcher.search(query, 10);
Assert.assertEquals(1, search.totalHits);
}
private IndexSearcher getIndexSearcher() throws IOException {
return new IndexSearcher(DirectoryReader.open(directory));
}
@Test
public void testToken() throws IOException {
Analyzer analyzer = new StandardAnalyzer();
TokenStream
tokenStream = analyzer.tokenStream("myfield", new StringReader("Some text content for my test!"));
OffsetAttribute offsetAttribute = tokenStream.addAttribute(OffsetAttribute.class);
tokenStream.reset();
while (tokenStream.incrementToken()) {
System.out.println("token: " + tokenStream.reflectAsString(true).toString());
System.out.println("token start offset: " + offsetAttribute.startOffset());
System.out.println("token end offset: " + offsetAttribute.endOffset());
}
}
@Test
public void testMultiPhraseQuery() throws IOException {
Term[] terms = new Term[]{new Term("content", "has"), new Term("content", "lots")};
Term term2 = new Term("content", "bridges");
//多个add之间认为是OR操作,即(has lots)和bridges之间的slop不大于3,不计算标点
MultiPhraseQuery multiPhraseQuery = new MultiPhraseQuery.Builder().add(terms).add(term2).setSlop(3).build();
IndexSearcher indexSearcher = new IndexSearcher(DirectoryReader.open(directory));
TopDocs search = indexSearcher.search(multiPhraseQuery, 10);
Assert.assertEquals(2, search.totalHits);
}
//使用BooleanQuery类模拟MultiPhraseQuery类的功能
@Test
public void testBooleanQueryImitateMultiPhraseQuery() throws IOException {
PhraseQuery first = new PhraseQuery.Builder().setSlop(3).add(new Term("content", "Amsterdam")).add(new Term("content", "bridges"))
.build();
PhraseQuery second = new PhraseQuery.Builder().setSlop(1).add(new Term("content", "Venice")).add(new Term("content", "lots")).build();
BooleanQuery booleanQuery = new BooleanQuery.Builder().add(first, BooleanClause.Occur.SHOULD).add(second, BooleanClause.Occur.SHOULD).build();
IndexSearcher indexSearcher = getIndexSearcher();
TopDocs search = indexSearcher.search(booleanQuery, 10);
Assert.assertEquals(2, search.totalHits);
}
}
相对于索引的创建而言,索引的搜索是使用频繁的。所以 IndexReader 是会经常使用的,我们很自然地想到应该将它设计成一个单例模式。但是索引增加、修改、删除以后,IndexReader 须要重新读取索引信息 , 使用 DirectoryReader 类的静态方法 openIfChanged 就可以达到目的,这个判断会先判断索引是否变更,如果变更,我们要先把原来的 IndexReader 释放。
Lucene 中还有一个 SearcherManager 类,可以用来管理 IndexSearcher。前面我也讲过,后面如果有时间,我们再来详细的说一下。

最后,欢迎关注我的个人微信公众号:业余草(yyucao)!可加作者微信号:xttblog2。备注:“1”,添加博主微信拉你进微信群。备注错误不会同意好友申请。再次感谢您的关注!后续有精彩内容会第一时间发给您!原创文章投稿请发送至532009913@qq.com邮箱。商务合作也可添加作者微信进行联系!
本文原文出处:业余草: » Lucene 实战教程第十一章详解 IndexSearcher 索引搜索器