
本博客日IP超过2000,PV 3000 左右,急需赞助商。
极客时间所有课程通过我的二维码购买后返现24元微信红包,请加博主新的微信号:xttblog2,之前的微信号好友位已满,备注:返现
受密码保护的文章请关注“业余草”公众号,回复关键字“0”获得密码
所有面试题(java、前端、数据库、springboot等)一网打尽,请关注文末小程序

【腾讯云】1核2G5M轻量应用服务器50元首年,高性价比,助您轻松上云
时序数据库最近几年正在大爆发,各搜索引擎的搜索指数也都是呈上升趋势的。

刚好最近也有人问到时序数据库,而这方面的资料也比较少,因此,我在这里浅谈一下,我对时序数据库的一些看法,不喜互喷!
我们先来看一个 DB-Engine 上的排名。

这份排行榜,排的都是时序数据库。比较来说,InfluxDB 的位置比较稳当;Kdb+ 和 Prometheus 近两年来上升势头很猛。
综合各方面的数据来说,时序数据库的兴起是有原因的。就拿无人驾驶来说,无人车在运行时需要监控各种状态,包括坐标,速度,方向,温度,湿度等等,并且需要把每时每刻监控的数据记录下来,用来做大数据分析。每辆车每天就会采集将近8T的数据。如果只是存储下来不查询也还好(虽然已经是不小的成本),但如果需要快速查询“今天下午两点在北京路,速度超过60km/h的无人车有哪些”这样的多纬度分组聚合查询,那么时序数据库会是一个很好的选择。
在比如,证券交易,智能家具,城市大脑等这些应用程序均依赖一种衡量事物随时间的变化的数据形式,这里的时间不只是一个度量标准,而是一个坐标的主坐标轴。
这就是时间序列数据,它渐渐在我们的世界中发挥更大的作用。目前,时间序列数据库(TSDB)已经成为增长最快的数据库类别。未来随着 5G 的到来,时序数据库将更加流行。
对时序数据进行建模的话,会包含三个重要部分,分别是:主体,时间点和测量值。套用这套模型,你会发现你在日常工作生活中,无时无刻不在接触着这类数据。
如果你是一个股民,某只股票的股价就是一类时序数据,其记录着每个时间点该股票的股价。
如果你是一个运维人员,监控数据是一类时序数据,例如对于机器的CPU的监控数据,就是记录着每个时间点机器上CPU的实际消耗值。
时序数据从时间维度上将孤立的观测值连成一条线,从而揭示软硬件系统的状态变化。孤立的观测值不能叫时序数据,但如果把大量的观测值用时间线串起来,我们就可以研究和分析观测值的趋势及规律。
时序数据的数学模型
上面介绍了时序数据的基本概念,也说明了分析时序数据的意义。那么时序数据该怎样存储呢?数据的存储要考虑其数学模型和特点,时序数据当然也不例外。所以这里先介绍时序数据的数学模型和特点。
下图为一段时序数据,记录了一段时间内的某个集群里各机器上各端口的出入流量,每半小时记录一个观测值。这里以图中的数据为例,介绍下时序数据的数学模型(不同的时序数据库中,基本概念的称谓有可能不同,这里以腾讯CTSDB为准):
- measurement: 度量的数据集,类似于关系型数据库中的 table;
- point: 一个数据点,类似于关系型数据库中的 row;
- timestamp: 时间戳,表征采集到数据的时间点;
- tag: 维度列,代表数据的归属、属性,表明是哪个设备/模块产生的,一般不随着时间变化,供查询使用;
- field: 指标列,代表数据的测量值,随时间平滑波动,不需要查询。

如上图所示,这组数据的measurement为Network,每个point由以下部分组成:
- timestamp:时间戳
- 两个tag:host、port,代表每个point归属于哪台机器的哪个端口
- 两个field:bytes_in、bytes_out,代表piont的测量值,半小时内出入流量的平均值
同一个host、同一个port,每半小时产生一个point,随着时间的增长,field(bytes_in、bytes_out)不断变化。如host:host4,port:51514,timestamp从02:00 到02:30的时间段内,bytes_in 从 37.937上涨到38.089,bytes_out从2897.26上涨到3009.86,说明这一段时间内该端口服务压力升高。
时序数据的特点
- 数据模式:时序数据随时间增长,相同维度重复取值,指标平滑变化:这点从上面的Network表的数据变化可以看出。
- 写入:持续高并发写入,无更新操作:时序数据库面对的往往是百万甚至千万数量级终端设备的实时数据写入(如摩拜单车2017年全国车辆数为千万级),但数据大多表征设备状态,写入后不会更新。
- 查询:按不同维度对指标进行统计分析,且存在明显的冷热数据,一般只会频繁查询近期数据。
传统数据库在时序数据场景下存在的问题
很多人可能认为在传统关系型数据库上加上时间戳一列就能作为时序数据库。数据量少的时候确实也没问题。但时序数据往往是由百万级甚至千万级终端设备产生的,写入并发量比较高,属于海量数据场景。
MySQL在海量的时序数据场景下存在如下问题:
- 存储成本大:对于时序数据压缩不佳,需占用大量机器资源;
- 维护成本高:单机系统,需要在上层人工的分库分表,维护成本高;
- 写入吞吐低:单机写入吞吐低,很难满足时序数据千万级的写入压力;
- 查询性能差:适用于交易处理,海量数据的聚合分析性能差。
Hadoop生态(Hadoop、Spark等)存储时序数据会有以下问题:
- 数据延迟高:离线批处理系统,数据从产生到可分析,耗时数小时、甚至天级;
- 查询性能差:不能很好的利用索引,依赖MapReduce任务,查询耗时一般在分钟级。
可以看到时序数据库需要解决以下几个问题:
- 时序数据的写入:如何支持每秒钟上千万上亿数据点的写入。
- 时序数据的读取:如何支持在秒级对上亿数据的分组聚合运算。
- 成本敏感:由海量数据存储带来的是成本问题。如何更低成本的存储这些数据,将成为时序数据库需要解决的重中之重。
基于上面的这些问题,时序数据库的诞生就是为了解决传统关系型数据库在时序数据存储和分析上的不足和缺陷的。
开源时序数据库对比
目前行业内比较流行的开源时序数据库产品有 InfluxDB、OpenTSDB、Prometheus、Graphite等,其产品特性对比如下图所示:
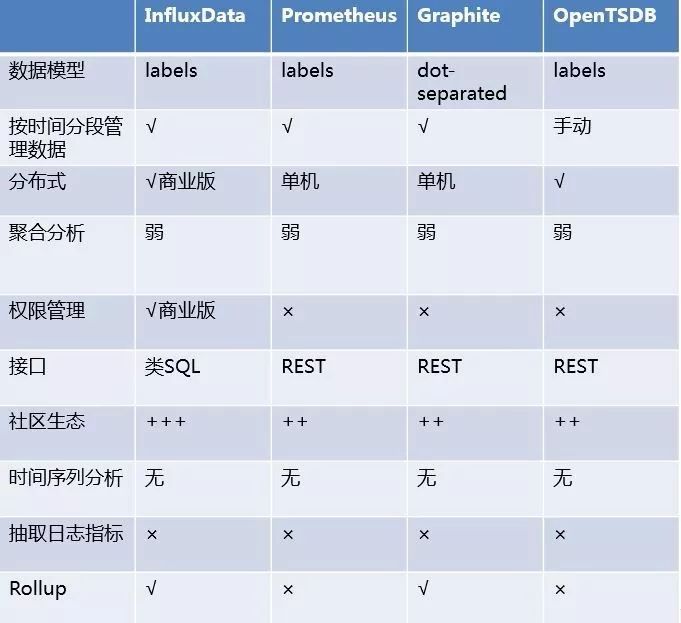
InfluxDB 是一个开源的时序数据库,使用 GO 语言开发,特别适合用于处理和分析资源监控数据这种时序相关数据,它目前是时序数据库中的佼佼者。
随着时间的推移,各大云厂商也都推出了自己的时序数据库。阿里巴巴的TSDB 团队自 2016 年第一版时序数据库落地后,逐步服务于 DBPaaS,Sunfire 等等集团业务,在 2017 年中旬公测后,于 2018 年 3 月底正式商业化。TSDB 在技术方面不断吸纳时序领域各家之长,开启了自研的时序数据库发展之路。
时序数据库目前还没有形成赢者通吃的局面,为国内的相关公司加油!

最后,欢迎关注我的个人微信公众号:业余草(yyucao)!可加作者微信号:xttblog2。备注:“1”,添加博主微信拉你进微信群。备注错误不会同意好友申请。再次感谢您的关注!后续有精彩内容会第一时间发给您!原创文章投稿请发送至532009913@qq.com邮箱。商务合作也可添加作者微信进行联系!
本文原文出处:业余草: » 时序数据库的前景与未来