
本博客日IP超过2000,PV 3000 左右,急需赞助商。
极客时间所有课程通过我的二维码购买后返现24元微信红包,请加博主新的微信号:xttblog2,之前的微信号好友位已满,备注:返现
受密码保护的文章请关注“业余草”公众号,回复关键字“0”获得密码
所有面试题(java、前端、数据库、springboot等)一网打尽,请关注文末小程序

【腾讯云】1核2G5M轻量应用服务器50元首年,高性价比,助您轻松上云
最近两年很忙,没多余时间写文章!之前的几年,我还写过不少,其中有很多系列是从根上理解来展开的,今天抽个时间,我们再来一篇《从根上理解 Redis RDB 的底层原理》。下面是正文:
我是个 redis 服务,我可能马上就要挂了!
我已经运行了好几年了,我的内存中存储着好多键值对。

如果我挂了,那样我内存中的数据就全没了。
我得想个办法,时不时把数据复制到硬盘上保存起来。我把这个伟大的计划,称为持久化计划。
停下手头的工作
由于我是一个单线程的,我要进行 RDB,我首先想到的最简单的办法,就是先拒绝新来的命令,开始将内存中的数据复制到硬盘。等拷贝完成后,再开始接受新命令。
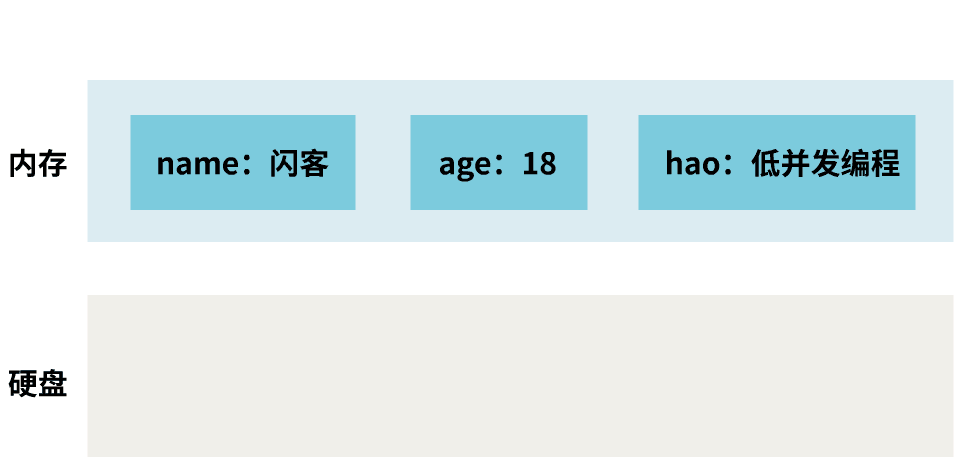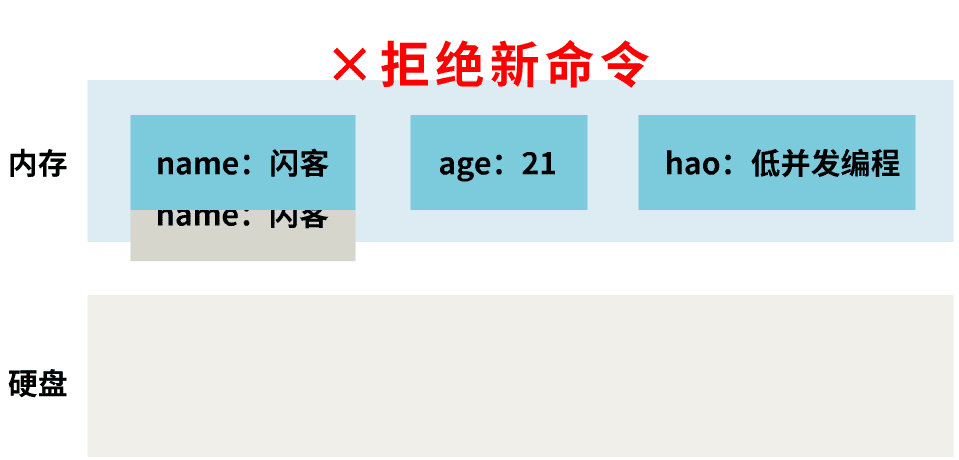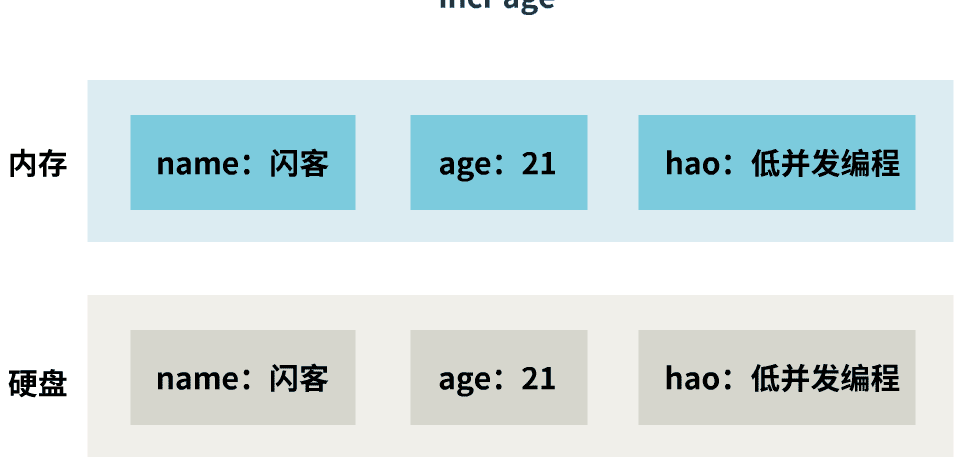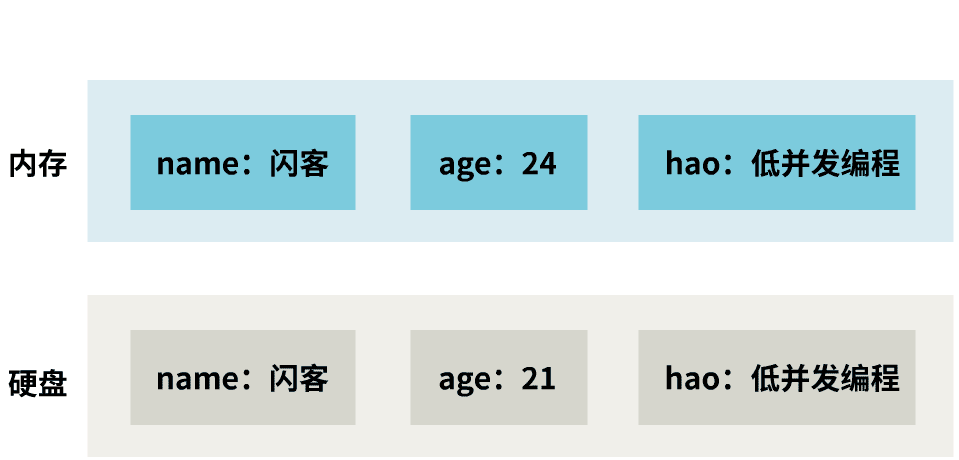
这样可以保证我拷贝的时候,没有新来的命令修改内存,也即保证了时点性。
简单说就是,我保存的是某一时刻的 Redis 内存状态。
但这样每次持久化都要阻塞客户端命令,肯定要被骂。
不停止手头的工作
我不想这么 Low,我的单线程高效率不是白叫的,我必须想办法进行高效的 RDB。
这好办,那我就不停止手头的工作呗,一边接受命令,一边做持久化,如下。
这样效率提高了不少,持久化不再阻塞客户端执行命令了。
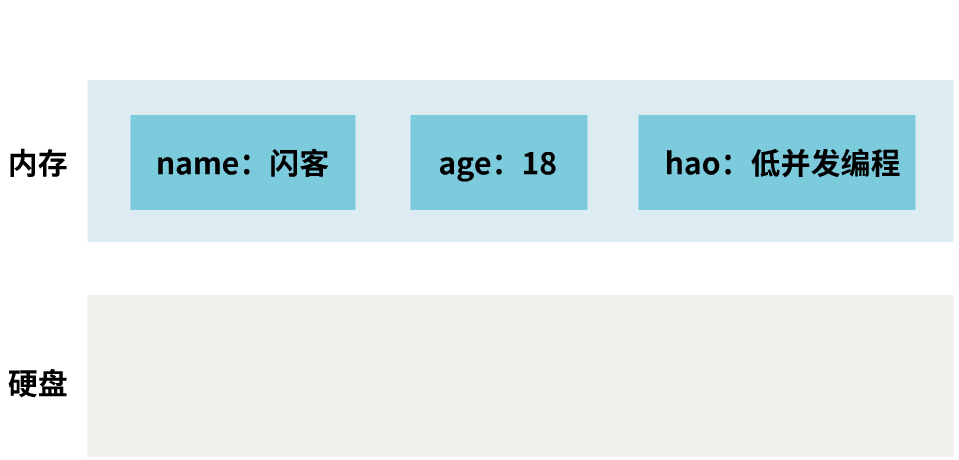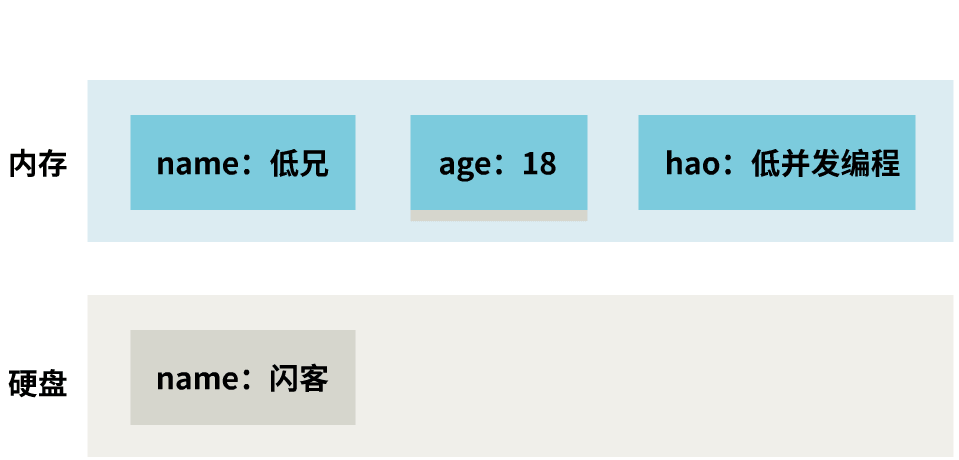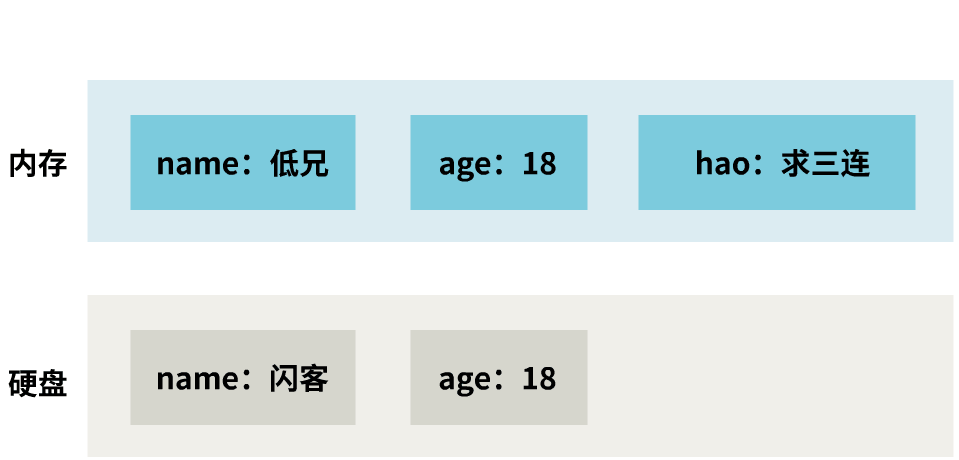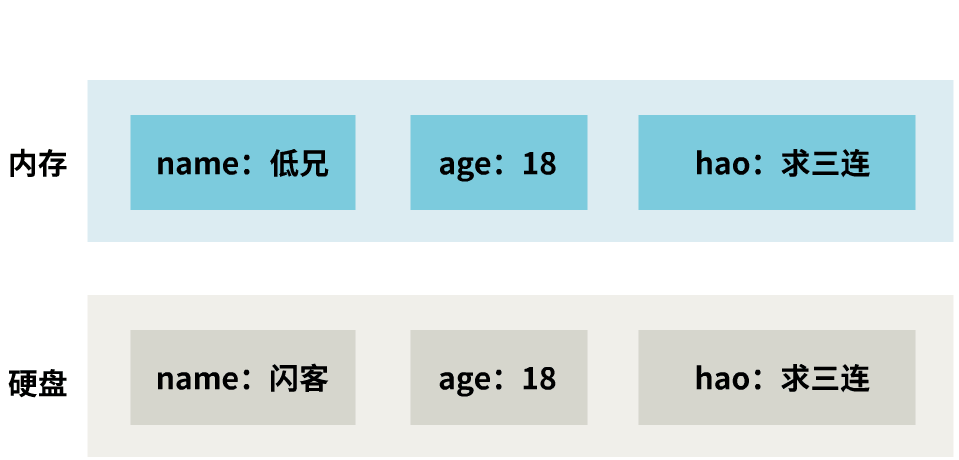
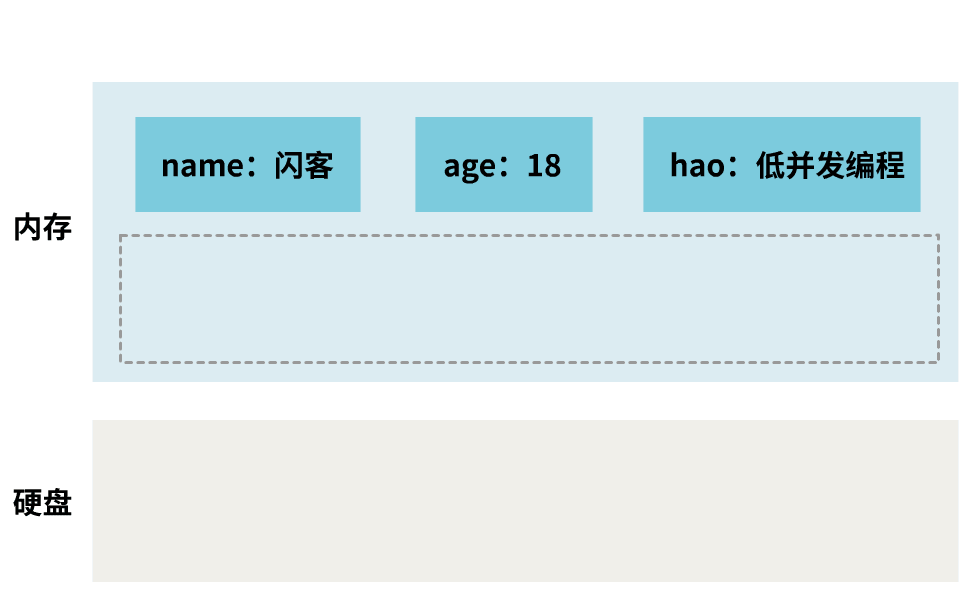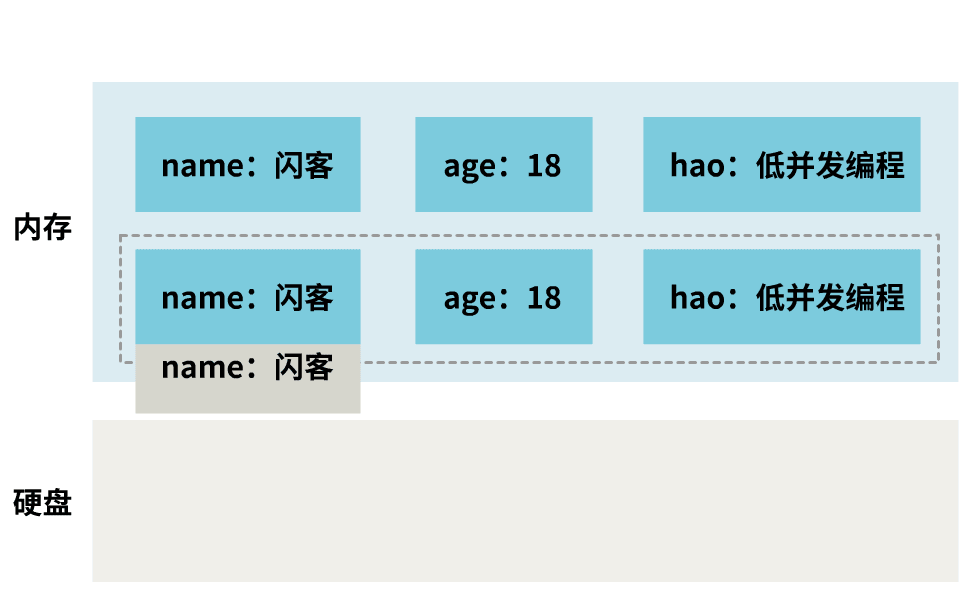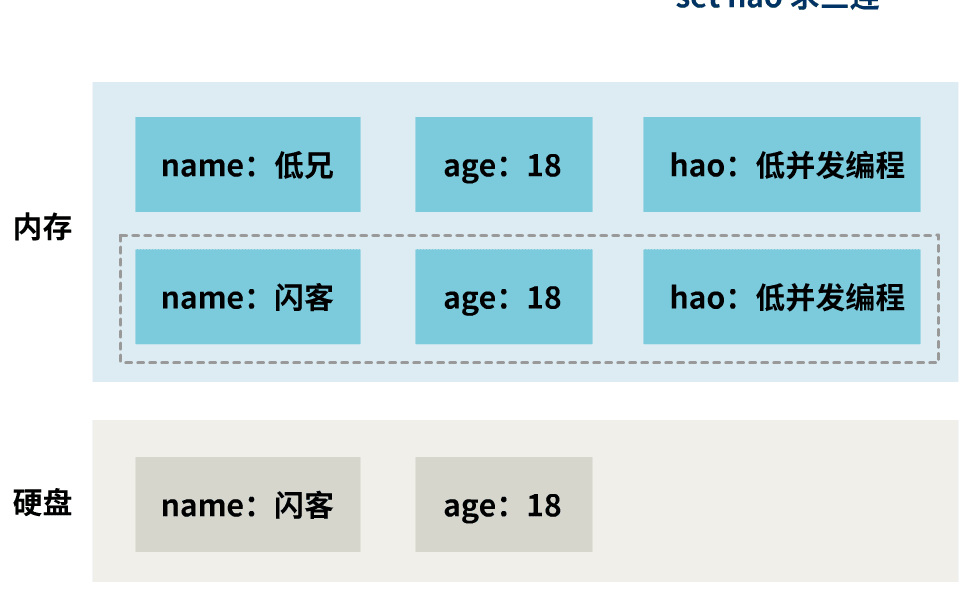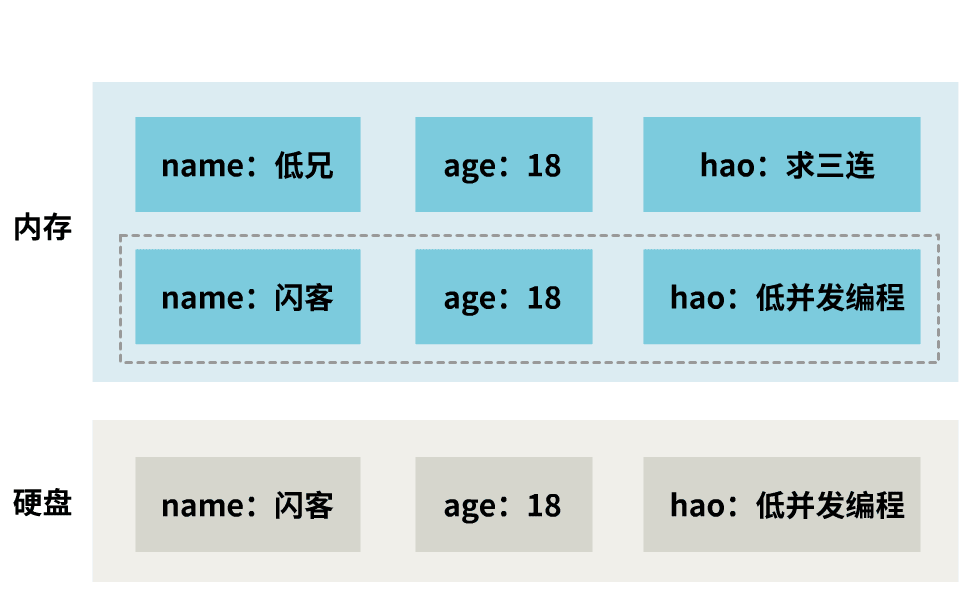
但是,你有没有注意到,内存中,某一时刻的数据,只有三种情况:

而此时硬盘中持久化的数据是:
闪客 18 求三连
它无法表示任何一个时刻的内存数据。
那这样的快照就失去了意义,也即没有保证时点性。
这显然也是不行的。
先复制一份内存
这可咋办呢?
停止手头的工作可以保证时点性,但阻塞了客户端。
不停止手头的工作,虽然不阻塞客户端,但又无法保证时点性。
真令人头大啊。
抓了一会头皮后,我冷静了下来,开始分析。
时点性是必须保证的,否则快照就没有了意义,那就只能尝试将阻塞客户端的时间变短一点了。
之前的阻塞客户端时间,是消耗在持久化,也就是内存拷贝到硬盘这个过程。
优化一下,先从内存中拷贝一份到另一块内存空间,然后再对这块新的内存空间进行持久化。
这样,持久化的过程不耽误客户端命令,同时不受客户端命令影响,保证了时点性。
而阻塞客户端的时间,仅仅是内存与内存之间拷贝一份数据的时间,相比于整个持久化过程,可以忽略不计。
完美!
带着这套完美的方案,我去找我的主人邀功了。
写时复制
我:主人,我做好持久化方案啦!
主人:嗯我看看… 哎呀,把内存复制一份,这个想法很好,但是差了点火候呀,你对操作系统了解的还不够深入。
我:啊,为啥呢?
主人:你想想看,你现在的目的,就是为了让持久化和处理客户端命令的这两个过程所用到的内存空间隔离开,是不是?
我:嗯嗯是的。
主人:对呀,那其实你只需要新建一个进程去做持久化的过程即可,不同进程之间的内存是隔离的,也就是新建一个进程,会将原有进程的内存空间完全拷贝一份新的。

我:啊,那这不是和我自己复制一份内存一样嘛,耗时差不多吧?
主人:我刚刚的图只是给用户的感觉是这样的,实际上,linux 采用了写时复制技术,在 fork 出子进程时并没有立刻将内存进行拷贝,仅仅是拷贝了一份映射关系,让它们暂时指向同一个内存空间。
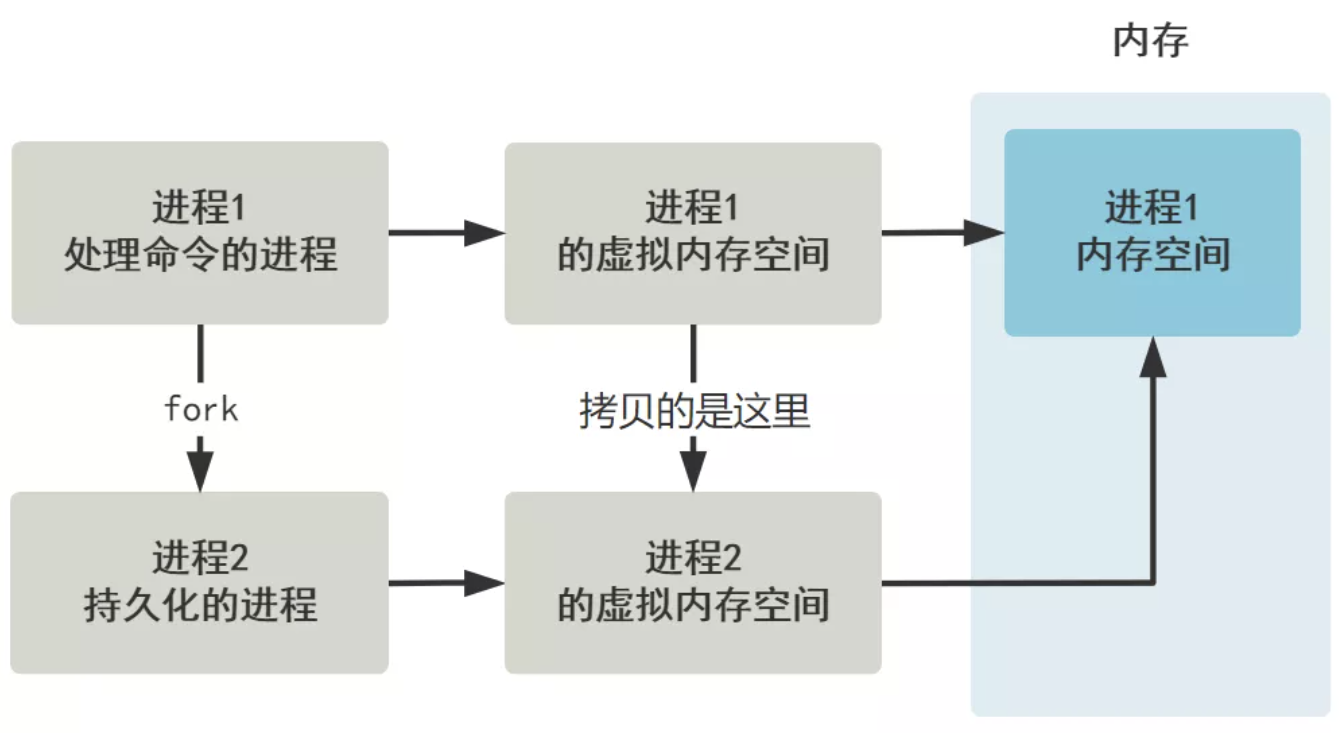
主人:而当父子进程对这块内存空间进行写操作时,才会真正复制内存,而且是以页为单位。
我:原来如此,也就是说,我可以利用操作系统的进程的写时复制内存的原理,来代替我自己复制全部内存这个方案,因为持久化过程,对内存的写操作想来也不会特别多,大多数值都是不变的,所以这样就提高了效率。
主人:是的,正是如此。
我:妙呀!
我赶紧把方案修改了,要持久化时我就 fork 一个子进程去做这件事,由操作系统的进程内存隔离的特征替我保证时点性,写时复制原理替我保证效率,也就是减少客户端阻塞时间,伪代码大概是这个样子。
void rdbSaveBackground() {
// 子进程处理(利用了操作系统的写时复制技术)
if ((childpid = fork()) == 0) {
// 落盘主方法
rdbSave();
}
}完美!
还没定结构呢
刚刚光顾着想持久化的过程了,还没定写到磁盘中的数据格式呢。
那就定一个呗。
假如我的 Redis 内存只有一条数据,是通过下面的命令写入的:
set xttblog 业余草那持久化后落到磁盘中的 rdb 文件将会是这个样子。
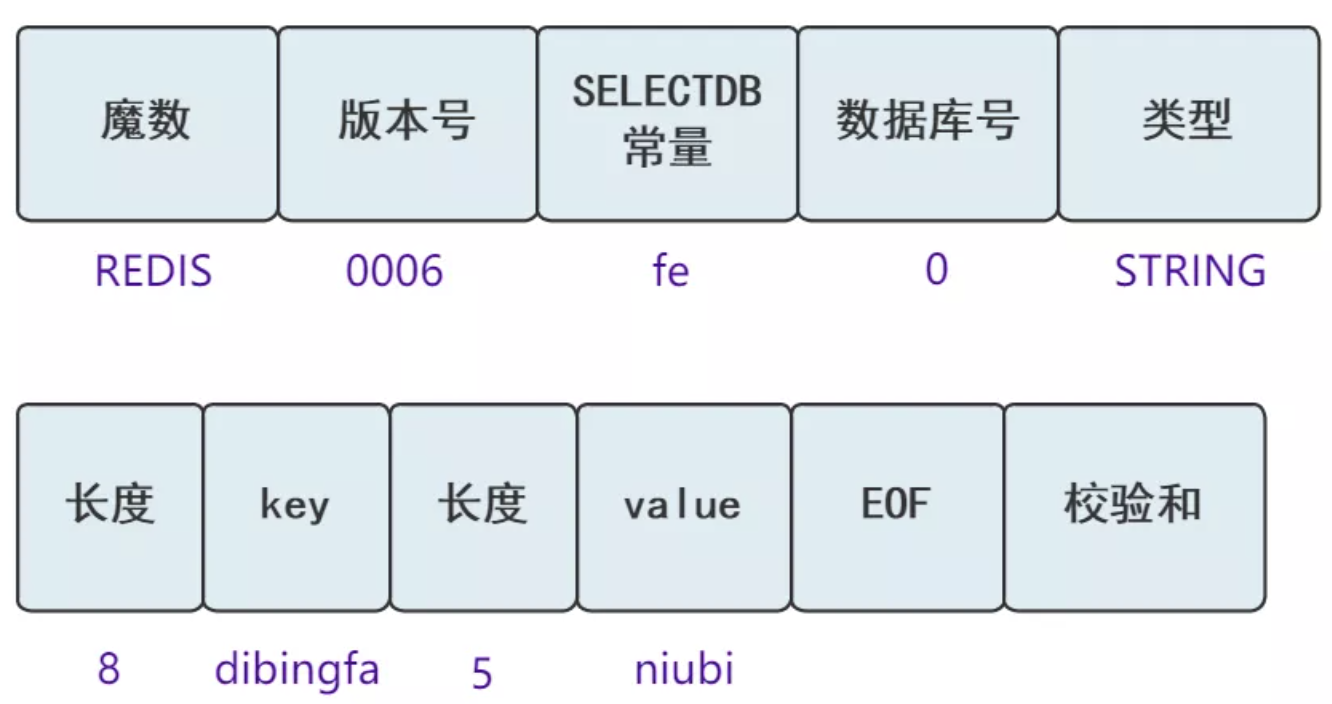
好了,大功告成,我再也不用担心自己挂了,会有人帮我从持久化文件中恢复我的内存数据的。
但没来得及持久化的,我就不管了。
具体什么时候进行一次持久化,我给主人留了一个配置
save m n表示 m 秒内数据集存在 n 次修改时,自动触发一次持久化。
主人也可以配置多个这样的配置项。
而我也好心给主人配了个默认的配置项,并写了段注释。
# Save the DB on disk:
# In the example below the behaviour will be to save:
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 10000 keys changed
save 900 1
save 300 10
save 60 10000我想以主人的英文水平,应该可以读得懂。
好啦,这回真的是大功告成了!
这个破玩意,我给起个名字,就叫 RDB。
没什么特别的含义,其实就是用我的名字作为开头,Redis DB 而已。
参考资料

最后,欢迎关注我的个人微信公众号:业余草(yyucao)!可加作者微信号:xttblog2。备注:“1”,添加博主微信拉你进微信群。备注错误不会同意好友申请。再次感谢您的关注!后续有精彩内容会第一时间发给您!原创文章投稿请发送至532009913@qq.com邮箱。商务合作也可添加作者微信进行联系!
本文原文出处:业余草: » 从根上理解 Redis RDB 的底层原理!